RSS in emacs:elfeed [EHWW]
RSS in emacs:elfeed [EHWW]
I've been trying some Emacs packages, including elfeed and meow, but the latter is not the topic of this post. I will briefly introduce elfeed package.
I use straight.el to install packages:
(use-package elfeed
:custom
(elfeed-feeds
'("https://dannypsnl.srht.site/rss.xml")))
elfeed-feeds is where you configure the feeds. Here I use my personal site as an example. Use M-x elfeed to open a buffer of elfeed. In this buffer, pressing G will fetch and refresh the feeds. Once articles are listed, pressing Enter will open the selected one. In reading mode, n and p move to older and newer articles, respectively.
Pattern Unification 演算法理論部分 [F6C1]
Pattern Unification 演算法理論部分 [F6C1]
在這篇文章裡面我想要探討 Elaboration Zoo 裡面的 pattern unification 演算法怎麼算出來的,以及在什麼時候成立。主要是了解我們怎麼導出等式:
超越 Elaboration zoo 中的合一演算法與隱式參數 僅是直覺的推理。在 Display map category 我們已經了解到,contexts 跟 substitutions 構成了一個範疇,而我們想要知道的是 epimorphism 的定義,所以 Kovacs 的第一步是把 epimorphism 定義改寫成更適合這個案例的定義
Definition. Epimorphism [local-0]
Definition. Epimorphism [local-0]
我們說 是 epimorphism iff
這也導出了 term 的事實:
我們關心一個 substitutions 中的子集:renamings
Definition. Renamings [local-1]
Definition. Renamings [local-1]
一個 substitution 如果純粹由變數構成,那麼它是 renaming,記成
而且 Renaming 有以下特性
- 如果只用到 中的變數至多一次,那麼 是 epimorphism
- 如果只用到 中的變數至少一次,那麼 是 monomorphism
- 如果只用到 中的變數剛好一次,那麼 是 isomorphism(context 的 permutation)
Definition. Embeddings [local-2]
Definition. Embeddings [local-2]
Renamings 還有一個子集叫 Embeddings,是 為 捨棄 0 到多個變數後組成的 context。
- 每個 embedding 都是 epimorphism
- embedding 一定是 identity
Renaming 總是能被分解為(這個動作叫 strengthening,可以延伸到 type/term 的 substitution 上)
其中 是一個 monomorphism,而 是一個 embedding
Pattern unification 問題是,在某個 context 下有等式
其中
所謂的 pattern conditions 是以下 3 個條件
- 是一個 epimorphism 跟 renaming,可以分解成
- 這個 meta variable 在 中不是自由變數
是 epimorphism 意味著 也是 epimorphism,因此 是 isomorphism,具有 inverse 。從初始問題出發
分解 得到
替換 得到
embedding 是 epimorphism
套上
inverse 對消
這促使我們定義 ,然後就只需要檢查 不是解的自由變量就可以了,原因參考 Elaboration with first-class implicit function types 的細節。直覺一點來說,本來的假定條件會導出 不是自由的,如果檢查卻發現它是自由的,就表示假定條件不成立。
最後
- 判斷 Renaming 是不是 epimorphism
- 分解 Renaming
- type/term 的 strengthening(如果 type theory 是 normalizing)
這三個演算法都是可判定的,因此 pattern unification 這個演算法是可判定的。而且由於分解唯一,解也是唯一的。
安裝 Guix [B4OI]
安裝 Guix [B4OI]
下載之後按照系統安裝文件描述的方式把 iso 燒錄到 USB or DVD,插入電腦開始安裝。基本上現在的引導介面已經跟 ubuntu 之類的老牌 distribution 相當了,只要按照螢幕上說的逐步回答就能設定完成。
它的 root 跟一般帳號是明確分開的,密碼也不同,在設定完 root 密碼之後會要求建立至少一個一般帳號。partition 分成兩種,按照需求選擇就好。最後選介面時有很多選擇,Gnome、KDE、Sway 都有,這個也是習慣用什麼就選什麼就行了。這之後就會開始安裝,跑完之後重開機(boot 管理要記得切換到安裝好的系統才不會又跑進 installer)。
到這裡就可以看 https://guix.gnu.org/manual/1.5.0/en/html_node/Getting-Started-with-the-System.html 文件開始編輯 /etc/config.scm 了。
2026 - Week 5 [2026-W5]
2026 - Week 5 [2026-W5]
Racket 中的 concurrent programming [local-0]
Racket 中的 concurrent programming [local-0]
想到就測試 rakka 跟 Racket coroutine thread 結果 native 還比較快XD,所以我就把 genserver 做成 Racket thread 封裝了 https://codeberg.org/dannypsnl/erl。至於為什麼 coroutine thread 這麼快,我猜可能 CS 之後有很大改善,我之前沒有注意到這點
Racket language server [local-2]
Racket language server [local-2]
racket-langserver 這個 PR 的目的是改善目前一團糟的測試體驗。現在的方式是啟動 subprocess 然後跟它的 stdio 互動,一來這意味著大量的系統資源需求,二來耦合這麼重就很難設計可以遠端連線的 server。所以第一步需要清理現在的設計,引入間接層讓測試只需要跟這個抽象部分互動就好
racket-llvm [local-3]
racket-llvm [local-3]
改善一下 racket-llvm 的文件,修復案例
2026 - Week 4 [2026-W4]
2026 - Week 4 [2026-W4]
試著寫了 JIT 框架,研究了 JIT: Write XOR Execute policy 怎麼實現。目前放在 https://github.com/dannypsnl/still-compiling/tree/develop/dynasm 中,目前還遠遠不成熟,可能做幾個 example 之後才會考慮釋出
Rakka 使用初體驗 [GMYW]
Rakka 使用初體驗 [GMYW]
最近發現 racket 生態系裡面出現一個 Rakka 程式庫,它似乎把 Erlang 大部分一階抽象都做出來了,這是我個人想像很久的寫法,所以我當然很有興趣去嘗試。我的第一個實驗是針對的 sauron 內部程式庫 collector 進行重構。collector 原本就是模仿 Erlang 的訊息傳遞方式來抽象,使用 rakka 之後,我直接把這些抽象邏輯寫成 GenServer 的形式。結果發現效果非常不錯
- 程式碼數量減少:collector 的程式碼量變成原來的大約三分之二。
- 維護性提升:整體結構變得更好維護。
所以之後遇到類似的需求,我就會考慮使用 rakka 處理,我就不用再寫處理訊息傳遞風格的樣板式重複程式碼了。而且它還實現了 EPMD protocol,可以跟其他 node 互動。
Display map category 捕捉了類型論的什麼面向? [tt-BBGG]
Display map category 捕捉了類型論的什麼面向? [tt-BBGG]
要理解 Display map category 的定義(參考 Categorical Logic and Type Theory, Definition 10.4.1),我們需要理解它的動機跟捕捉問題的方式,因此我們要觀察一個個相繼式(我假設讀者已經熟練相繼式定義的類型論),並用範疇論(category theory)的語言重述。
在用相繼式描述類型論時,公式
表示 可派生出類型 。對於所有 可派生的類型,我們用 表示,所以我們也會用 來表示上面的相繼式。Display map category 捕捉的第一件事就是 contexts 構成一個 category,我們用 記號表示這個範疇,並且我們要求 有 terminal object ,用來表示空的 context。
context 的構造方式只有兩種: 是一個 context;context 加入一個類型 得到的 還是 context。
因此 也常被稱為 telescope
在相繼式中如果我們寫
我們的意思是 ,對於每一個 ,都能找到 ,我們稱「 實現了 」。
但上面那樣寫有問題,因為 沒有憑依,因此正確的通用寫法是記錄成
這表示 參考 中的變數,並實現了 ,這叫做一個替換。
對 type 套用替換 [local-0]
對 type 套用替換 [local-0]
如果我們同時有 跟 ,那我們可以對 進行替換得到:
換句話說,我們用 完成了一個逆變,記成 。
對 term 套用替換 [local-1]
對 term 套用替換 [local-1]
用相繼式時
表示 在 中有類型 ,當然,這裡隱含的前提是 。
而替換同樣可以在 term 上作用:
對替換套用替換 [local-2]
對替換套用替換 [local-2]
但我們也知道替換 也能看成一個 term,所以同樣可以對它套用替換!
這說明了替換可以結合!我們經常記成 。
而很明顯的,對於所有 有一個「引用變數 來實現 的不變替換 」,所以我們想把每個替換 視為 中的 morphism 。這裡需要證明幾件事
- 對於給定的 ,可能的 的 collection 是一個集合。由於所有替換都涉及對 的引用(或是有限多的類型生成規則)並做出一個有限構造,所以可以用歸納的方式比較,這讓證明是唯一的,因此這些替換是 set
- 對 來說有 。根據定義就知道了
- 替換要有 associative 。這個不好證明,就我所知都是對規則進行 induction 得到(參考 Substitution Without Copy and Paste 的 §4.3)
現在我們要進入 Display map 的部分
Definition. Display map [local-3]
Definition. Display map [local-3]
對於 與 ,我們有 ,這叫做 display map。提醒一下這個相繼式是
考慮逆變,就得到
唯一確定了一個類型,也就是說現在每個 type 都被一個某一些替換代表了。這也可以說其實我們在看 這些 morphisms。
term 的表示 [local-4]
term 的表示 [local-4]
同理可以放到 term 上,對於
可以視為
也就是說每一個 term 都可以看成替換
到這裡我們發現,這個模型很好的捕捉了 syntactic categorical 的觀點,把類型論的句法特性都保留了下來。前面說過每個替換都有逆變,現在我們要證明逆變是一個 functor:
Proposition. 逆變是 functor [local-6]
Proposition. 逆變是 functor [local-6]
對於任何 ,我們把逆變看成 slice category 的函數 ,要檢查這是否是 functor,我們想要證明兩件事:保留 identity 且保留 composition。
Proof. [local-5]
Proof. [local-5]
套上 display maps 的規範,知道逆變會產出一個 pullback:

這直接證明了 ,所以 ,表示 保留了 identity。
要證明 composition,可以用 pullbacks 的結合知道如果 跟 的頂點 up to isomorphism 是同一個,因此這兩個 morphism 是一樣的,證明了也保留 composition。因此每個替換誘導出的逆變都是 functor。 □
既然 是個 functor,那在 display map category 裡,我們可以用 的 right adjoint 表示 product,而且加上 Beck-Chevalley 條件:存在一個 natural isomorphism,讓我們可以把 product 用替換推來推去而不會變成不同的東西。
weak sum 同理,只是變成 的 left adjoint,同樣要有 Beck-Chevalley 條件保證 coproduct 可以被推來推去而不遺失。strong sum 則是把條件強化到 display maps 組合一定是 display map,這蘊含 weak sum 條件。
我們前面完全沒有提到 這種形式,而確實這是 display map categorical 方法的額外條件:weak equality 用 diagonal 的 left adjoint 表示,還是用 Beck-Chevalley 條件避免遺失。strong equality 規定 diagonal 是 display map,蘊含 weak equality。
對細節有興趣的讀者可以看 Paige Randall North 的 slide:Homotopical models of type theory
現在我們看到,display map category 除了捕捉 type theory 的 syntactic 特性,還可以用直觀的範疇論語言表述 type theory 的數種特徵,成功的讓我們用範疇論的觀點來檢視類型論。
現代 - 商業、科技與政治交織的空間 [U5YI]
現代 - 商業、科技與政治交織的空間 [U5YI]
讓我們先從 LLM 開始談起,我認為 Context Widows 的觀點很適合開始理解問題在哪裡。問題不在 LLM 或是廣泛的 AI 領域有用或是沒用,正如 Context Widows 一文自己所說跟我從其他地方看到的,正面的產出確實存在,像是
- 蛋白質折疊
- 材料科學
- 用壓縮映射模擬星系演變
而可質疑的問題也一直存在:幻覺、缺乏理解。更不用說直接的負面影響
- 氣候
- 佔用能源(包含在天災時電網供電給計算中心而不是醫院)
- 剽竊創意
Context Widows 真正要談的是,比起問 LLM 有沒有用,更恰當的問題是:LLM 能否有效地融入科學知識的創造、驗證和傳播過程中?
LLM 能否有效地融入科學知識的創造、驗證和傳播過程中? [local-0]
LLM 能否有效地融入科學知識的創造、驗證和傳播過程中? [local-0]
由於一項技術的潛在用途並非其實際用途,而實際用途又取決於採用該技術的機構、機構試圖解決的問題以及機構用作衡量成功的既有指標。所以 Context Widows 認為探討 LLM 與科學的關係,等若詢問 LLM 出現之前,科學界已經運作著怎樣的體系?
我們知道當代科學界的主導是引用體系,隨著時間發展,引用體系已經改變它本要量測的對象;科學家會調整自己的行為以最佳化指標。Context Widows 也駁斥用古德哈特定律「當一個指標成為目標時,它就不再是一個好的指標」來解釋這件事,因為古德哈特定律只認為指標是問題,但 Context Widows 一文認為有問題的是需要指標才能運作的組織形式。
在這個背景下,LLM 雖然有其他的功用,卻只會加速學術界的固有邏輯:更多的發表。引用文中的話來說
LLM 並非經濟學家(一群熱衷於用貶低維度的方式來消除意義的人)所稱的科學激勵「結構」的創造者。相反,這項技術恰好出現在這樣的背景下,提供了一種更快的方式來生產系統所獎勵的成果。
而很明顯的,這不局限於學術界中,搜尋引擎的誕生改變了網路,SEO 變成很多網站在意的事,從而產生了內容農場這樣製造垃圾的存在。
到這裡我們先總結 Context Widows 的結論:
LLM 並非科學出版功能失調的始作俑者;它們繼承了這種功能失調,加劇並使其運行得更快。就像一種通常無害的病原體在免疫功能低下的患者體內肆虐一樣,它們指出了問題所在,但如果將它們視為問題的全部,那就大錯特錯了。人們或許會希望這種加速發展能加劇矛盾,讓系統如此迅速地產生大量劣質內容,最終讓問題變得無可辯駁。但是,正如我們現在應該都明白的那樣,系統可以無限期地處於功能失調狀態,而荒謬本身並不會自我糾正。這種加速發展究竟會導致崩潰、適應,還是只是延續現狀,並非技術本身的問題,也無法透過關於技術能力的爭論來解答。答案將由運行這個計畫六十年的機構來解答。
於是現在我們可以更進一步的詢問:LLM 能否有效的融入商業的創新、運作和責任之中?
LLM 能否有效的融入商業的創新、運作和責任之中? [local-1]
LLM 能否有效的融入商業的創新、運作和責任之中? [local-1]
同樣的,這使得我們去問:LLM 出現之前,商業運作著怎樣的體系?
在經濟學追尋公司的意義時,Milton Friedman 在 1970 年提出 The Social Responsibility of Business Is to Increase Its Profits,直譯大概就是「企業的社會責任是增加利潤」,這是當代企業的主流追求與試圖實踐的理想。這有什麼樣的後果?
Paul 有兩篇相關的 thread,很清晰的闡述了當代的企業環境
- https://hachyderm.io/@inthehands/113603661215753448
- https://hachyderm.io/@inthehands/115793003693199462
儘管我們大多數人都生活在現代企業地獄般的環境中,仍然無法理解大企業的運營究竟有多麼嚴重的破碎,以及它們在多大程度上依靠虛假、欺騙和胡言亂語來運作。
所以,為什麼公司部署 LLM 呢?Paul 讓我們從底線來看:XX 公司的新 AI 客服描述不存在的功能,或是叫人們去吃釘子或膠水。會怎樣嗎?嗯反正他們以前那些不幸的、缺乏訓練的、工資微薄、像泥土一樣被對待的客服人員(過去負責處理所有的客戶支援),實際上也沒有幫助人們。由於 XX 公司對吞吐量的要求如此之高,並且對問題關閉的激勵如此之大,以至於他們的客服人員帶領人們白費力氣,罵人或放棄回應。LLM 不會罵人,不會放棄回應,吞吐量極高。它在帶領人們白費力氣上「遠遠」比人類更有效率,而且有時候僅僅靠運氣,它實際上是對的!
從底線來看,部署 LLM 其實沒有那麼糟糕!所以現況其實是
商業活動為世界提供的實際價值如此之少,以至於用快速、自動化的廢話取代緩慢的人類廢話似乎是一場勝利。
所以對於採不採用 LLM,我們可以問的問題是:如果它是錯誤的,那麼重要嗎?Paul 以特斯拉為案例:特斯拉正在銷售這些「顯然」還沒有準備好迎接黃金時段的自毀汽車,它們會用事故後打不開的車門將人們困在裡面,然後將他們活活燒死。而且他們仍然在銷售大量這些東西。如果對他們來說這樣都無關緊要,那有多少虛假和危險的商業環境是可以被他們接受的?
LLM 是假的?又怎樣呢?商業也是如此。
更具體的說,LLM 會對管理層帶來什麼影響?對糟糕的組織領導人來說,讓擁有專業知識的下屬不去檢查他們的想法基本上就是成癮性藥物。那 LLM 豈不是就是不會拒絕他們任何「高妙」想法的完美下屬?這是一種強大的心理力量,促使我們快速地往採用 LLM 滑動,無關乎這是否有用。
所以同樣的,LLM 表現出的,是對既有商業實踐的加劇與加速,放大既有的功能失調。在 LLM 以前同樣有 08 年的次貸風暴,遵循一樣的系統運行規則而致。
監控資本主義提出現代商業的核心邏輯是:資本的來源是販售預測;最容易被預測的人群,是被監控甚或控制的人群。因此獲利的動力會驅動大規模的監視與控制。
按吳修銘的話來說,即使是 Google 最大的反對者也很難說監控資本主義談的是 Google 的主要目的。但這可以被視為一個特別黑暗的隱喻,指向現代商業實踐的最糟結果。而現實中最接近的,是中俄等專制政權已經學會怎麼用現代技術影響他國的政治。
- 《讀賣新聞》報導台灣政府正高度警戒中國透過操縱輿論介入選舉
- 法國國際廣播電台報導歐洲如何應對俄羅斯的政治宣傳和軍事威脅?
再次的,LLM 提供了加劇破壞社會討論的一種方式,即用無限量的劣質資訊破壞言論場域,但這是因為網路早已逐漸侵蝕了公眾對談的能力。參見 Are we too connected to social media? An explanatory research the problematic social media use in self-esteem, phubbing and procrastinating behaviour。
LLM 能否有效的融入人的成長、交流與生活中? [local-2]
LLM 能否有效的融入人的成長、交流與生活中? [local-2]
LLM 能否有效的融入人的成長、交流與生活中?這當然是一個複雜的問題:LLM 出現之前,現代人類是怎麼成長、交流與生活的?
- 現代的主流成長方式,是未成年人類放到學校;而成年人上網看一些什麼如何投資、如何成長的東西,比如人們會看教你如何閱讀的影片,但不會真的去閱讀。對了,老闆想要成長 — 我們就讓老闆「看見」成長。
- 現代的主流社交方式,是在稱之為社群媒體或是社交平台(像是 threads、IG、FB)的地方對幽谷大喊,由演算法控制人們看到什麼(你很好奇為什麼 meta 好像持有前述的所有平台?這是很好的好奇)
- 現代的主流過活方式,是必須上 8 小時以上的班,換取大概能過活的薪水,在剩餘的時間想辦法娛樂自己,我們勉強稱之為生活
LLM 會怎麼影響,要看 LLM 有哪些具體的施展位置。
在學校逐漸提高效率要求的情況下,你要怎麼譴責老師:用 LLM 生成題目、改答案、規劃教學?
在課業繁重的情況下,學生要怎麼不用 LLM 生成作業?尤其是成績如果能因此提高,而系統獎勵成績時?
人們要怎麼分辨出 LLM 生成的留言然後避免被影響?
人們要怎麼在生活壓力越來越大時不對 LLM 宣洩情感?至少它不會罵我們
人們要怎麼在不因為能對 LLM 下令而被權力損傷?
oh, I just realized: does this mean that AI gives everyone the chance of the brain damage humans get from too much power too long?
要怎麼在搜尋引擎預設就提供 LLM 合成答案時去搜尋原始文章,確認內容?
要怎麼在繁重的工作壓力下保持生活?
上述的問題,有些出自商業邏輯,有些跟我們的社會運作有關,有些是因為人類的生理能力。再次的,LLM 加劇我們的問題,但不是唯一的原因。要讓 LLM 技術不對人類造成危害,就要在這些具體的案例中找出我們的解答。
注意到,這篇文章的目的不是號稱 LLM 全然的不好,或是商業多麽的灰暗;即使是最荒謬的公司中都有很多好人試著改善問題;學術界就算深受引用指標影響,也依然有大量有用的研究出產。最糟糕的莫過於直接跳過具體案例的討論,做出這個世界已經完全沒有救的結論。
這篇文章的目的是,從我有限的觀察與閱讀中,指出具體的商業、科技與政治問題,並且試著改善它們。如果問萬事揭曉:打破文明演進的神話,開啟自由曙光的全新人類史最重要的意義是什麼,我會說是 Graeber 指出人類具有想像並構造自己的政治的能力,遠超過當代人對自己的想像。或許我們可以試著打造一個世界,減少指標的需要、降低對效率的要求、更關心你我周遭的人、更注重環境對我們說的話,這不是什麼烏托邦,衝突不會簡單的消失,但我們需要真的開始對話跟行動,這一切才有出路。
2025 年 [2025]
2025 年 [2025]
今年開源的一點貢獻
- 自己弄了個網站生成工具 tr
- 弄懂怎麼生成 induction principle
- 參與了一點 Yoxem 的 SICP 台語翻譯計畫
- agda-mode-vscode 提示 unicode 符號輸入方式
- 讓 magic-racket 可以開啟 macro 展開過程的互動 GUI 用來除錯
- racket-langserver 的維護,今年底突然獲得管理權限xd
然後我下定決心研究了 epub 檔案格式,讓我更清楚可以對這些書籍檔案做什麼xd。因為年初我自己立的目標是看懂 mirror symmetry,數學我今年大致上學了
mirror symmetry 的表示論前提
- -linear category
- cochain complex: 一系列 vector spaces (或是 graded vector spaces)加上一個 degree 1 的 linear map
- cohomology: 按組成取 也是一個 graded vector space,這就是 cohomology 了
- algebra 與 category
- Twisted complex
另外從微分幾何的方向看了一點物理學的對稱性怎麼用來描述費米跟玻色場。不過這些內容的意義為何?要解決什麼問題?似乎又回到需要代數幾何的基礎上,因此這裡得先放著了。
- preadditive/abelian category
- 一點 commutative algebra
- 一點 Lie algebra
今年末尾嘗試寫了各種 agda,讀了點 HoTT 中的 higher inductive types 跟 synthetic geometry,結合上面需要代數幾何的部分,讓我想往 synthetic geometry 的方向試試,或許先看看幾篇相關論文的未來研究方向跟未解問題?
閱讀 [local-0]
閱讀 [local-0]
- 監控資本主義時代 上卷: 基礎與演進/ 下卷: 機器控制力量:除了這本書本身指出的極端情況,還有數個對現況的相關看法應該一起吸收,我應該會再寫一篇文章寫這方面的感想
- 萬事揭曉:打破文明演進的神話,開啟自由曙光的全新人類史:作者認為大眾對人類發展史的看法深受盧梭與霍布斯的遺緒影響,而考古與人類學證據足以駁斥這些觀點
- 慈禧: 開啟現代中國的皇太后:這是在 mastodon 上看別人看很有趣就去買的書,作者盡力基於歷史證據描繪了一個與學生時代課本所述完全不同的慈禧
- 不實在的現實:以演化為基本的公理的話,我們會推導出什麼樣的世界觀?我覺得有關聯、也很有啟發性的是訪談 Michael Levin 討論的事情
- 勤儉魔法師的中古英格蘭生存指南、侑美與夢魘繪師、翠海的雀絲、日煉者:嚴格來說日煉者我只看了一半,不過應該很快就能看完xd
- 裸顏(Till we have faces):這本小說的劇情很明顯不能按照字面意思去讀,賽姬跟歐若要解釋成一個人或是兩個人都可以,而「神」的意義也明顯有多重意義,每次閱讀應該都會投射自己的人生感想進去吧xd
技術性的東西其實比較好寫,做到哪裡就說什麼。今年六月的時候去台中找朋友,雖然大罷免沒有成功,但很高興台灣有這麼一群人,民主的重點從來都不是政黨,而是表達意願、付諸行動的公民。台灣的未來、人類的未來,目前看起來都比較灰暗,我不會指望明年就會有什麼差別,但願我們能學會不輕視人文、理解不同的文化、解決共同的難題。
Rhombus 用標記運算自動排序資料 [programming-0005]
Rhombus 用標記運算自動排序資料 [programming-0005]
最近在研究 Shrubbery Notation 怎麼實現 operator 優先序的過程中(卡關中),又發現 Rhombus 的 meta 功能中有不少有趣的東西,比如現在要介紹的功能:標記運算。要使用這個功能,必須在開頭宣告
#lang rhombus/and_meta
或是
#lang rhombus/static/and_meta
語言。接著定義
annot.macro 'AscendingIntList': 'converting(fun (ints :: List.of(Int)) :: List: ints.sort())'
這會在我們寫下
[3, 1, 2] :: AscendingIntList
時,得到 [1, 2, 3] 而不是 [3, 1, 2],因為這個標記會自動進行排序運算!
具體的 simplicial set: Torus [math-001J]
具體的 simplicial set: Torus [math-001J]
simplex 要怎麼跟幾何扯上關係?這是因為 up to homotopy,我們可以把幾何形狀變形成用一群三角形(確切的來說是一些 simplex)表示的形狀。這裡要講的案例 Torus 是一個二維度的幾何曲面,一般定義成 並畫成
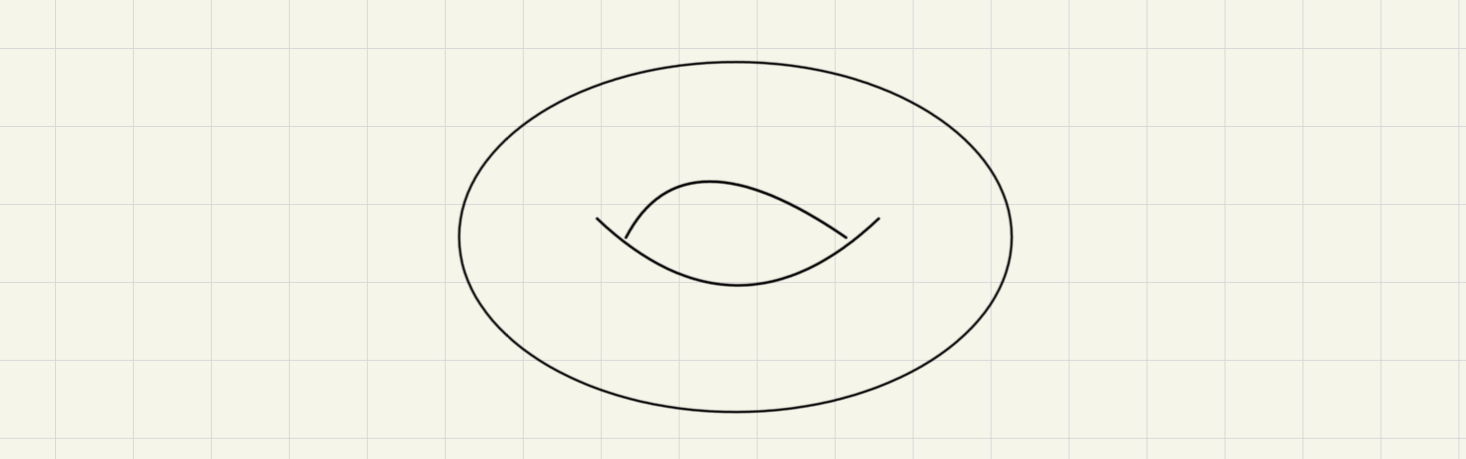
要怎麼三角化呢?通常會簡化成
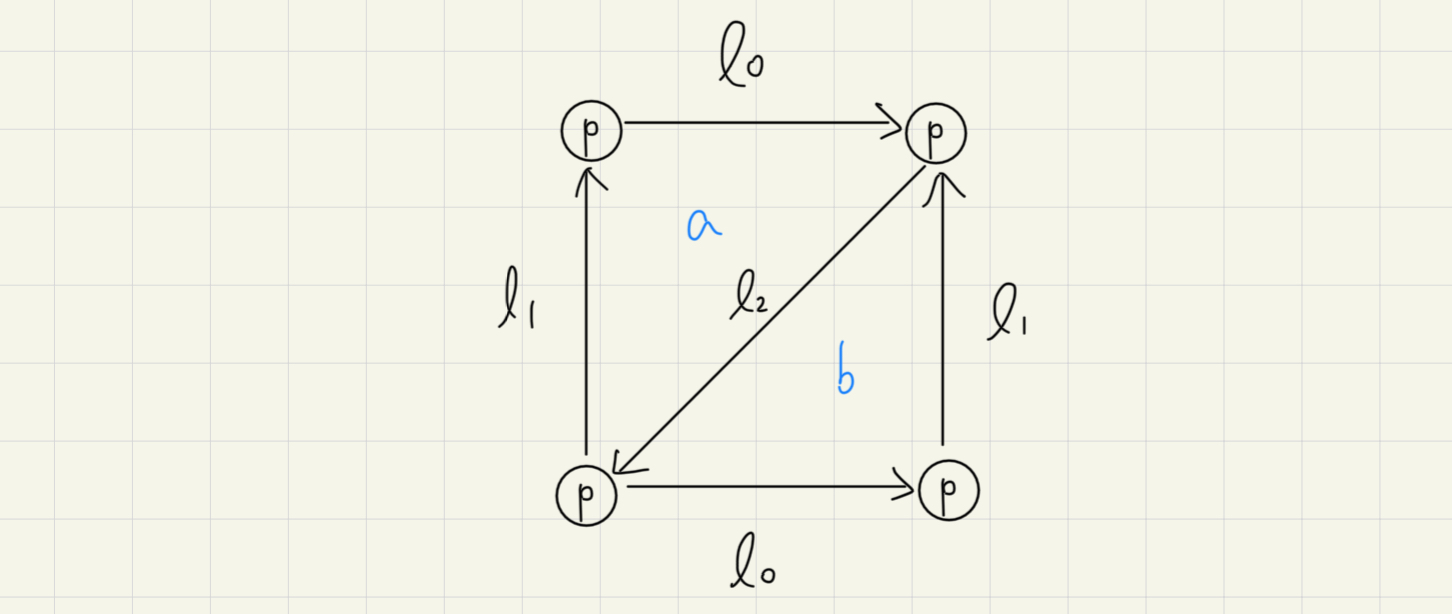
這怎麼變成幾何形狀的?注意到標為同一個名稱的那些線,那表示那其實是同一條線。這需要定義一個 simplicial set (Hint: 根據定義是個 contravariant functor),其資訊如下:
視為其幾何實現(geometrical realization):
每個 topological space 都導出一個 simplicial set ,每個 -simplex 都是 到 的連續函數:
每個連續函數,都給出了連續變形的過程;第二部分則是取 restriction,保持邊界關係。我下面展示如何逐漸變形來解釋其意義:
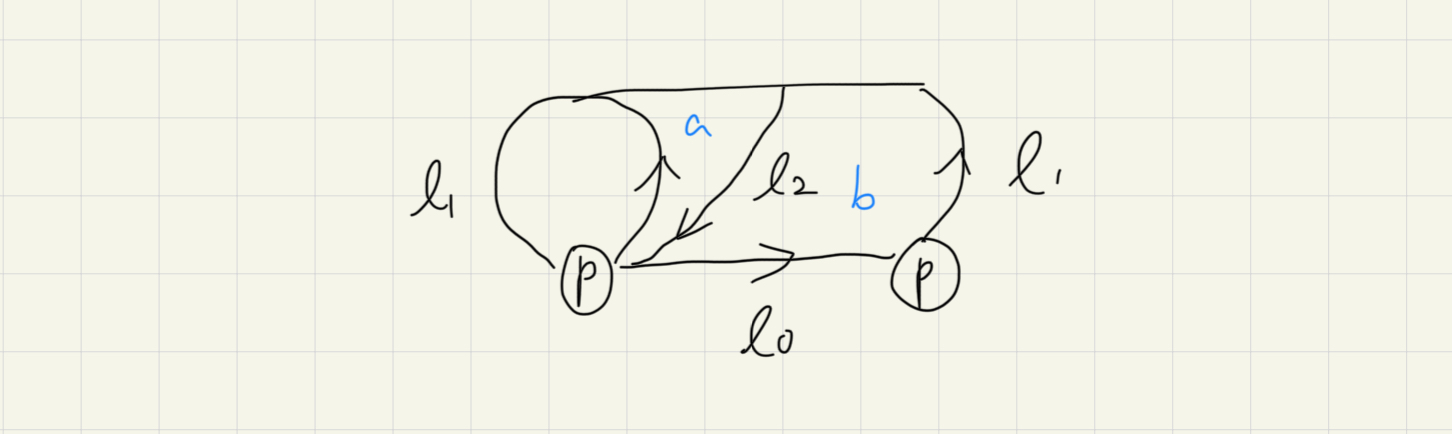
接著把管子對接
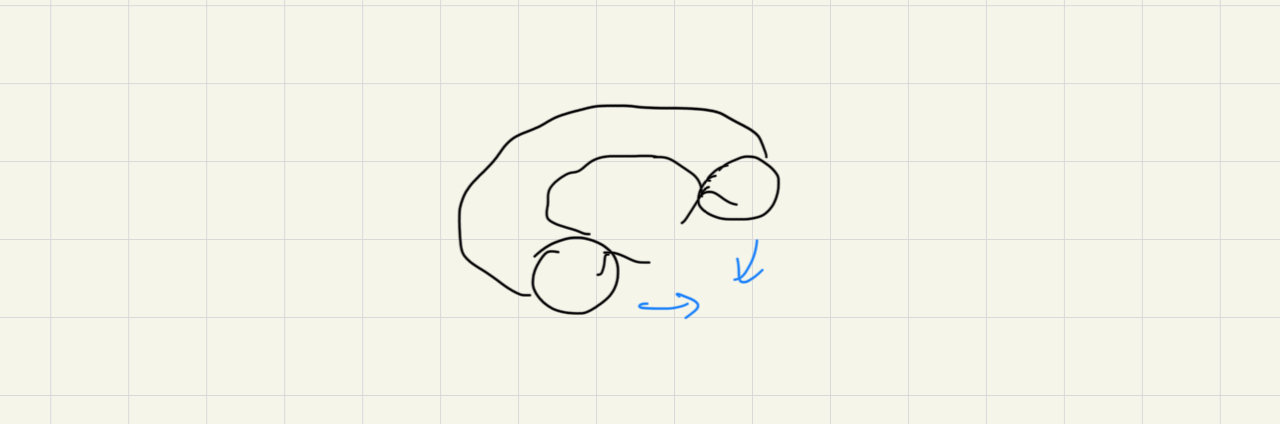
這確實是 Torus 的模型。
Integrating Mathlive into editor.js and Thoughts on Note-Taking Systems [programming-0004]
Integrating Mathlive into editor.js and Thoughts on Note-Taking Systems [programming-0004]
editor.js is a free, block-style (composable) editor with universal JSON output. Hence, it's a nice foundation for building your own rich-text editor.
mathlive is a math editor for the Web, specifically a custom HTML element with functionality to edit math formulas:
<math-field> x^2 + y^2 = 1 </math-field>
editor.js is extensible. Specifically, when creating an editor.js instance, one can provide customized tools to it:
new EditorJS({
holder: editorContainer,
autofocus: true,
tools: {
header: Header,
underline: Underline,
strikethrough: Strikethrough,
list: List,
}
})
These tools are node packages you need to install. As you can see, editor.js is highly modular, which is good because I'm going to add a new tool here. I'm going to show how to build a mathlive tool called Formula for editor.js (and perhaps I'll extract it as a package in the future).
A custom tool requires some basic setup, which is common to all tools
class Formula {
static get toolbox() {
return {
title: "Formula",
icon: "...",
};
}
constructor({ data }) {
this.data = data;
this.wrapper = undefined;
}
}
- A tool is a JS class
- In
toolboxwe can configure the title to show and the icon (which is a string of svg syntax) - We need to restore from data when constructing the tool (when loading from existing JSON!)
- and we need a wrapper (a HTML element) to store the UI of this tool
Then we need to define how to store data into the output JSON, so we define save method
save(blockContent) {
return {
latex: blockContent.value,
};
}
The blockContent is what the render method returns. We'll look at that part now
render() {
this.wrapper = document.createElement("math-field");
this.wrapper.setValue(this.data.latex);
this.wrapper.macros = {
RR: "\\mathbb{R}",
};
this.wrapper.mathVirtualKeyboardPolicy = "sandboxed";
this.wrapper.addEventListener("focusin", (evt) =>
window.mathVirtualKeyboard.show()
);
this.wrapper.addEventListener("focusout", (evt) =>
window.mathVirtualKeyboard.hide()
);
this.wrapper.addEventListener("keydown", (e) => {
const navigationKeys = [
"ArrowLeft",
"ArrowRight",
"ArrowUp",
"ArrowDown",
"Home",
"End",
"Backspace",
"Delete",
"Enter",
"/",
];
if (navigationKeys.includes(e.key)) {
e.stopPropagation();
}
});
return this.wrapper;
}
This function is quite long, but let's break it down
- We assign the HTML element
math-fieldto the wrapper - Set the value of the math-field to the LaTeX formula loaded from data (which can be
undefined) - Define macros for LaTeX input
- Configure the policy and focusin/focusout event handlers to automatically open the virtual keyboard when the user focuses on the math-field
- Add an event listener to intercept keys that would otherwise cause you to lose focus on the math-field (remember that editor.js is an editor, and those keys would trigger other operations in the background editor)
- Finally, we return the wrapper, this HTML element will be the UI element of this tool
At the end, remember you also need to import css of mathlive in HTML
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/mathlive/mathlive-static.css" />
How to package Mathlive JS code depends on your bundler - that's an entirely separate issue that I won't cover here.
Now that the technical details are covered, I can discuss the motivation. Basically, most editors split math formula input into two phases: When you focus on it, it show the original LaTeX syntax so you can edit it. When you focus out, it use KaTeX to render the formula result. But that's messy!
This model makes it easy to miss small problems, that's why there are many small typos in complicated formulas. WYSIWYG is the tool to solve this, and mathlive is such editor I need.
The full plan - though I'm not sure if I'll actually do it - is a complete note-taking system for academic knowledge. Some great tools include forester, Heptabase, Obsidian, etc. However, they all have some rough edges for example
- forester has no editor part (there are some external editor projects though)
- I can't contribute to codebase of Heptabase
- Obsidian's format in long period is problematic
- An Obsidian editor extension can't be ported to non-markdown formats, so notes taken here can't be ported to forester, for example
I have to say these aren't problems with the tools themselves, but I do want a tool that has WYSIWYG + portable format (JSON is good enough) + searchability.
Of course, to keep learning progress of mine, I can't spend all the time on a tool - working on problems and reading papers are much more important for learning.
sauron supports find references in project [programming-0003]
sauron supports find references in project [programming-0003]
sauron now supports find references of a definition in a whole project scope at commit: 3f78957a. This is a final piece of my IDE development for Racket, I had this idea three years ago, but get completed till now. This is because the resource stability of Racket get a huge improved, make this possible, I don't have detailed number, but the same program three years earlier will take down DrRacket.
After the above nonsense, I should quickly explain the idea, it can be break to a few steps
Everytime the project-directory is change (this is a configuration item), send update command to files' maintainer
In each collector, record entries of reference like this: key is filename of definition and identifier of definition, value is the binding location (filename, start, and end position)
When user use Cmd+B/Click, check the cursor is on a definition or on a binding. If cursor is on the later, open list-box to pick a reference/binding, and the selection will bring user to a new location
Now, let's look at the result: a definition in a.rkt, a provide and a local reference/binding, and a reference from another file b.rkt. Three references are showed in the list-box
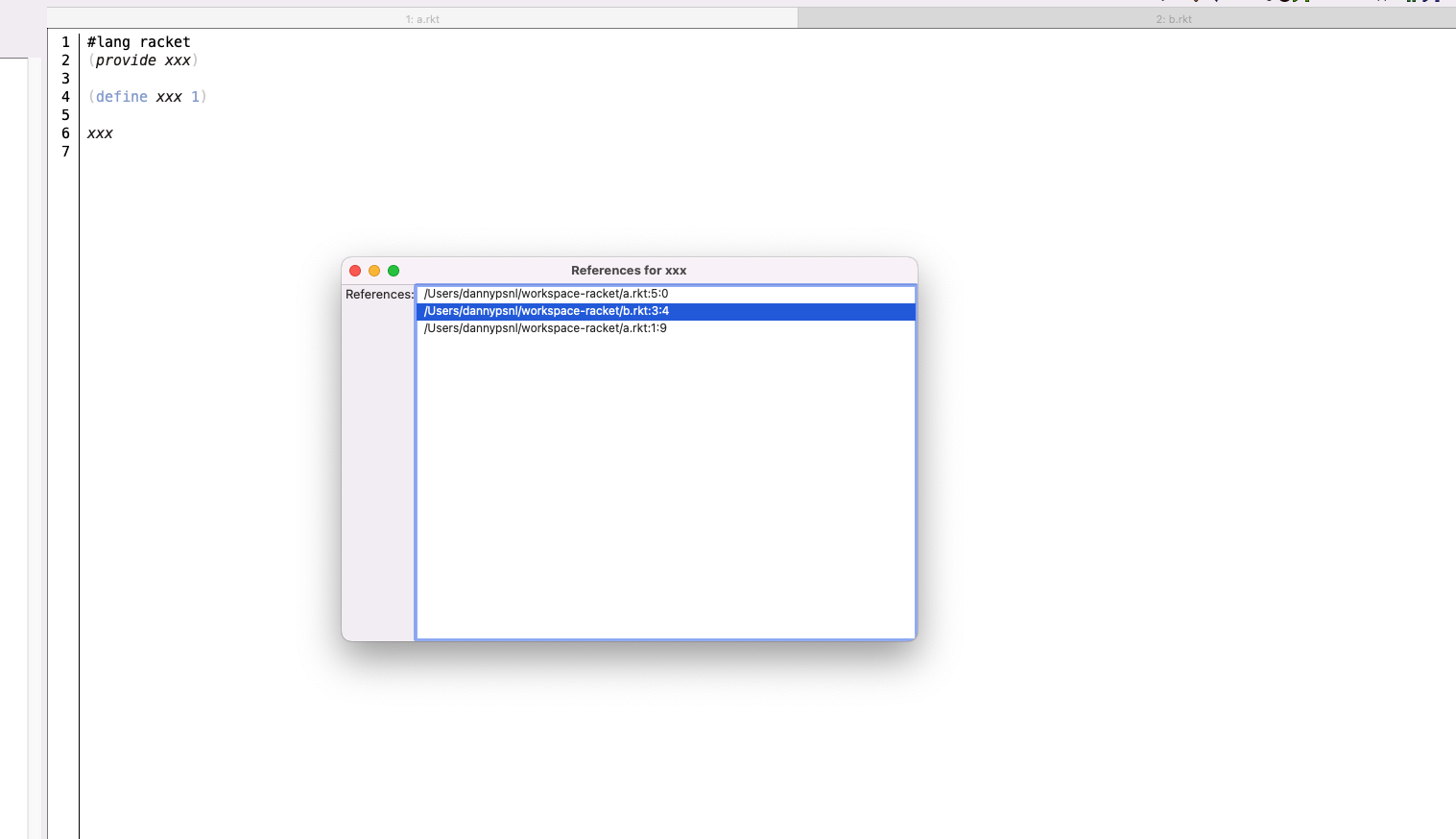
After click the item, the frame move to binding location at b.rkt.

Anyway, this is a nice end for this project, in the future I will more focus on racket-langserver because it can help more users.
TeXmacs [software-0008]
TeXmacs [software-0008]
最近因為朋友提及,所以真正嘗試了 TeXmacs https://www.texmacs.org/ 這個軟體,感受到什麼是所見即所得應有的樣貌,於是想寫下一點介紹。由於 TeXmacs 做的特別好的是數學公式編輯,所以我們集中在這件事上。在 TeXmacs 中輸入 $ 就會立即創造一個 math 區塊,用 Ctrl + $ 則會創造置中的 math 區塊($ 係指 Shift + 4,本文的快捷鍵皆為 MacOS 上的情況,在其他系統需注意差異)。
cursor 的所在區塊會被淺藍色框標記,範例如下

被選擇的區塊,會用紅色標記。用鍵盤或是滑鼠都可以選取

在 math 區塊中輸入分數時,鍵入 \frac 然後按下 Space,就會出現上下兩個區塊

其中紫色的是 cursor,可以用上下鍵切換要在哪個區塊繼續輸入

次方也是同理
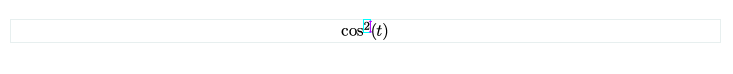
對於等號,也有特殊的操作可以使用,比如選擇等號後按下 Ctrl + A,就會在正上方出現輸入區塊


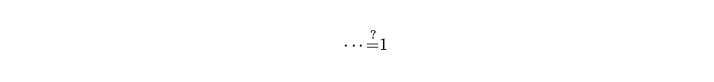
最後,還有一些數學常見的段落,都已經寫成樣板可以直接插入:
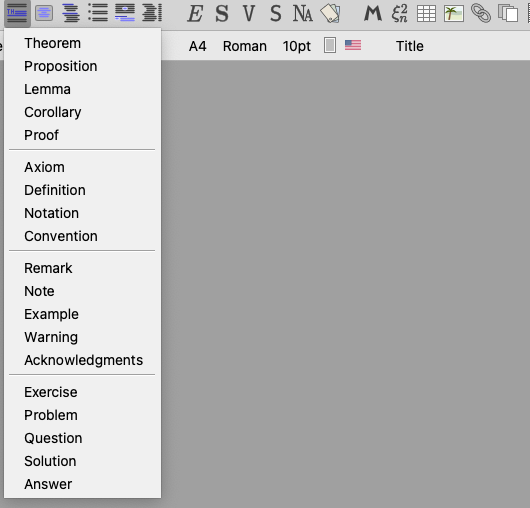
插入結果

My exploring Borsuk-Ulam Theorem [math-000U]
My exploring Borsuk-Ulam Theorem [math-000U]
My exploration (around April, 2025) of Borsuk-Ulam theorem began with trying to prove the Lyusternik-Shnirel'man closed theorem for and . While I could grasp it intuitively, constructing a rigorous proof proved elusive.
This led me to tackle the Borsuk theorem directly: For every continuous function , there exists a point such that .
The Failed Stereographic Approach
My initial idea was to decompose using North/South stereographic projections—the natural atlas for . This approach not quite work here: the N/S maps send the projection point to nowhere (or must change codomain to one-point compactification), making any function decomposed this way necessarily discontinuous.
Refinement: Finite Projections
I then considered pulling the projection point outward along the N-S axis, forcing projections into finite regions to maintain continuity. This insight—that continuity constraints force us to work in bounded regions—became crucial to my understanding.
Following this idea to examine the N/S map decomposition, after compressing infinity back to , the continuity requirement also necessitates pulling back the neighborhood, leading to the same conclusion as the outward projection: the region must be finite.
At this moment, I learn the relations between different description of Borsuk-Ulam (Some applications of the Borsuk-Ulam Theorem).
The Breakthrough
My proof strategy ended up opposite to the classical development. I first established a lemma:
Lemma: Let be continuous and antipode-preserving. Then there exists such that .
The details can be found here, the key is bound an open set of that contains and is the image of rest two open sets on . Hence, for some
The Proof
For the main theorem, define . Two key observations:
- is continuous
- is antipode-preserving:
Applying the lemma: there exists such that , which means , hence . Proof complete.
The "wrong" approach turns out is useful in lemma, and provides a more concrete view about the problem.
After this, I also found Borsuk-Ulam Implies Brouwer: A Direct Construction, which is the same approach, and use cube version.
Determinant 的意義 [math-000Q]
Determinant 的意義 [math-000Q]
從矩陣非常難看出 determinant 的意義,但它其實具備幾何的意涵:對 個向量張出的高維平行體的體積影響。
矩陣 可以視為張量 ,向量張出的高維平行體可以表示為 exterior product 。因此定義 如下:
這表示 把 映射到 所得的新高維平行體的體積相對於先前的高維平行體的比例(可能會正負轉換)。
補充:當 時。 階 skew-symmetric tensor 的空間 很明顯只有一個維度,這個空間在 Lectures on the Geometry of Manifolds 中叫做 Determinant line of 。此時 全都是 trivial space(只有 元素)。
部落格遷移 [blog-0000]
部落格遷移 [blog-0000]
最近終於自己寫了個 site generator tr,這套機制確實是解決我很多問題,所以就開始遷移舊的部落格了。原則上大部分文章或是筆記都不會跟過來,因為這也是趁機丟掉一些已經過時/太簡單的筆記的機會,tr 讓我可以直接嵌入 wiki/nLab 來取代解釋基礎的定義。
NixOS 需要定期清除 generations [software-0000]
NixOS 需要定期清除 generations [software-0000]
這是今天遇到的問題,更新系統時它提示 /boot/ 的空間不足以安裝 efi 檔案了,直接砍 /boot/EFI/nixos/ 裡面的檔案是沒有用的,因為 NixOS 的 generations 會重新生成這些資料。所以正確的作法是先執行下面的指令
cd /nix/var/nix/profiles
裡面會有很多像是 system-數字-link 這樣的 soft links,每一個對應一個 NixOS 的 generation。把太古老的 generations 刪掉,執行
nix store gc
這會跑一段時間(如果你跟我一樣太久沒有清理就需要很久),結束之後再次更新系統就可以了。
何謂 elaboration? [cs-0004]
何謂 elaboration? [cs-0004]
elaboration 指的是轉換沒有語意的表面語法(surface syntax 或是說 source code)到有語意的語言表示(language representation)的過程,這樣講可能有點抽象,所以需要一些例子。試問 foo(a, b) 這段 Go source code 有語意嗎?事實上是沒有,因為只有在 Go compiler 經過
- 讀取文字
- 解析語法取得語法樹
- 型別以及其他檢查
現在這段程式碼才會在 Go compiler 內部用某種資料結構表示,而 Go compiler 可以相信這段程式碼是滿足 Go 規範的程式,這樣才是有語意的語言。這個觀點一開始對你來說可能蠻怪異的,但我們可以仔細來看這樣定義的好處
- 有些語言如 Fennel https://fennel-lang.org/ 刻意把自己變成另一個語言 Lua 的另類文法,在語言表示層面要求共用一樣的語意。Fennel 還支援了 macro 系統
- 語法可以作為片段,嵌入到任何位置,只不過後續的檢查階段可能拒絕嵌入後產生的語法,因為這樣產生的程式依然可能是語法或是語意不正確的,比如使用 C 語言的 preprocessor 寫程式就經常會遇到這樣的問題。能把語法記錄下來並在別的地方展開的程式就叫做 macro,LISP 的 elaboration 經常叫做 expander
Macro system [cs-0005]
Macro system [cs-0005]
雖然 C 的 preprocessor 也被稱為 macro,但跟 LISP、Elixir、Julia 比起來就差很多的原因是
- C 對語法的原始位置放棄追蹤
- C 對 macro 的輸入跟輸出都沒有基本的檢查,也沒辦法對不同輸入做出反應
而常見的 LISP macro 過程則是:
- reader:
TEXT -> S-expression - 使用者定義的 macro:
S-expression -> S-expression - expander:
S-expression -> LISP
elaboration 前對語法樹進行操作的能力就是 LISP 最大的特徵,這使語言使用者可以自行發展他想要的語法,Clojure 做得比傳統 LISP 更好的地方就是這裡它採用的 edn 能表示比 S-expression 更多的資料,如 hashmap。
什麼是 subroutine? [cs-0006]
什麼是 subroutine? [cs-0006]
subroutine 在 C 語言被稱為 function,Fortran 中則分出 function 或是 subroutine,剩下還有一些語言使用 procedure 這個名稱。
Fortran offers two different procedures: function and subroutine. Subroutines are more general and offer the possibility to return multiple values whereas functions only return one value. https://fortranwiki.org/fortran/show/procedure
我把定義 subroutine 為一個指令語言編寫程式的模式,在組合語言裡面,我們並沒有函數名稱這種東西,相對的,其實只有指令的位址,所以組譯語言通常會提供區塊名稱來標記位址,比如 a:,那你可能已經想到了,如果我跳轉到 jump a 是不是就能執行 a 的內容了!是,但你要怎麼跳回來呢?所以 subroutine 就被發明了:找個 register 放一下要跳轉回來的位址就好啦!於是一個 a 呼叫 b 的程式就寫成
a: store ret (here+1) jump b ... b: ... jump ret
(here+1) 是為了跳過 jump b 這個指令,而 ret 就是一個特殊保留的 register,專門用來讓 subroutine 使用。你會發現,ㄟ這樣是不是沒有傳遞參數?沒錯,所以更完整的故事是,CPU 會乾脆設計一整套傳遞參數應該用哪幾個 registers 跟 stack 偏移的慣例,叫做 calling convention。
這就是所謂的現代 CPU 是為了 compiler 設計。不遵守這些慣例你的程式還是能動,但你的程式就會跟其他 compiler 為這個 CPU 吐出來的程式很難溝通。
作業系統的行程排程 [cs-0007]
作業系統的行程排程 [cs-0007]
在一些非常簡單的作業系統實現裡面,會乾脆讓 user process 自己決定要不要讓出 CPU,怎麼讓?就是把自己當前的 stack pointer address 以及 registers 狀態儲存到記憶體裡面去,通常是 kernel 提供的一個 struct,然後跳轉到另一個 process 去。
這樣的話這是 user process 自己決定讓給誰,一般其實也不是這樣實現的,而是 user process 只有呼叫 yield 把自己暫停,下一步轉移給誰交給 kernel 決定。比如 Linux 就有
int sched_yield(void)
這個函數。
但要是 user process 不小心陷入無限迴圈怎麼辦?所以更常出現的是所謂的搶佔式排程,kernel 分配 time slice 並且封裝 process,並且設定計時器硬體中斷來確保自己可以定時查看狀態,這樣 process 在 slice 用光之後(或是它的指令執行完畢)就可以被切斷。
Transformation induced dual basis [math-000D]
Transformation induced dual basis [math-000D]
Manifolds and Differential Geometry
Let be a basis of vector space , and let be a basis of dual space . Now if is another basis of , then there is an induced basis for dual space .

Proof
By Kronecker-delta
can see that if then the equality is hold. We can use Penrose notation to show the idea.

Algorithm. Elaboration zoo 中的合一演算法與隱式參數 [tt-0006]
Algorithm. Elaboration zoo 中的合一演算法與隱式參數 [tt-0006]
程式語言為了讓使用者省略不必要的輸入,必須為使用者推導內容,這種需求催生了合一這種類型的演算法。比如很多程式語言允許泛型,比如下面的 OCaml 程式碼
let id (x : 'a) : 'a = x
Elaboration zoo 這個教學專案,它的程式碼要解決的,是一類更複雜的程式語言,叫做 dependent type 的系統中的合一問題,這類系統最重要的特性,就是類型也只是一種值,值也因此可以出現在類型中,但這就比較不是本篇的重點,有興趣的讀者可以閱讀 The Little Typer 來入門。在解釋完它的合一之後,我會介紹它隱式參數的解決方案
Algorithm. 合一演算法的過程 [tt-0007]
Algorithm. 合一演算法的過程 [tt-0007]
假設有程式碼
let id {A : U} (x : A) : A := x
let id2 {B : U} (x : B) : B := id _ x
這裡 id _ x 中的底線表示「省略的引數」,被稱為 hole,我們並沒有明確的給它任何值,比如 B。在展開這個 hole 時,我們用 meta variable ?0 替換它。但 meta variable 必須考慮 contextual variables 的 rigid form,因此進行套用得到 ?0 B x。這引發問題
什麼是 contextual variables?為什麼 contextual variables 是 B 與 x? [tt-0009]
什麼是 contextual variables?為什麼 contextual variables 是 B 與 x? [tt-0009]
答案是,這些是 ?0 能看到且實際內容未知的變數,只能用 rigid form 替代
什麼是 rigid form? [tt-000A]
什麼是 rigid form? [tt-000A]
rigid form 是 dependent type 中即使是 open term 也必須先進行計算而被迫在實作中出現的一種值;由於 meta variable 而被迫出現的值則叫做 flex form
現在我們手上有的 term 是 id (?0 B x) x,現在執行 id (?0 B x),我們得到型別為
的 term
注意到 中兩個 來源不同,不可混用,我用顏色表示它們的 scope 其實不同這件事
現在進入到把這個 term 套用到 x 上的環節了,因此觸發 是否是 的 term 的合一計算,我們概念上紀錄成
現在合一演算法必須找出合適的 來滿足等式。我們知道 應該是某種 lambda
,顯然 就會給出我們想要的答案,但這部分要怎麼做到?elaboration zoo 的演算法分成三個階段
Invert [tt-000B]
Invert [tt-000B]
這裡的重點是,既然 已經套用了 與 ,因此就創立關聯它所創立的 lambda 中的變數到其 contextual variables 的映射(mappings)是
Broken pipe (os error 32)現在右手邊的 term 只需要看自己的每個 rigid form 有沒有被指向,只要這個映射裡面查找到有變數是指向 rigid form 自己,即反過來創立 rigid form 指向新名字的映射。比如說我們右手邊的 term 是一個 rigid form ,因此得到的反映射是
Rename [tt-000C]
Rename [tt-000C]
在上一步中得到的反映射是
用這個映射去改寫右手邊 term 的內容,就得到等式 ,而解則是 。
Lambda 化 [tt-000D]
Lambda 化 [tt-000D]
最後真正構造一個 lambda abstraction,就得到了
安插隱式參數的方法 [tt-0008]
安插隱式參數的方法 [tt-0008]
在最開始的程式碼
let id {A : U} (x : A) : A := x
let id2 {B : U} (x : B) : B := id _ x
裡面,其實 {} 中的綁定叫做隱式參數,這表示我們其實也可以用 id x 來調用該函數。但這時候要怎麼知道需要補一個 hole 進去呢?elaboration zoo 作者提出的簡易方案就是區分 implicit type 與 implicit application,如此一來,當一個 implicit type 被 explicit apply 的時候,我們就知道要安插 hole 了
以 id x 而言,如果要明確的用 implicit 調用它,就必須寫成 id {B} x,在語法就進行明確的區分。
這時候跳回去看「contextual variables 是 能看到且實際內容未知的變數」就更能了解其理由了,因為已經能明確知道其內容的變數,如
let x = t
x 就是指向 t 的情況,若右手 term 是 x,其實也會是 t 去進行 unify。若右手 term 已經是 rigid form 又可參照,就更不需要成為 contextual variables,因為其 solution 就是把右手 term 原封不動放入,在反轉 map 的時候,只要記得這個 rigid 是非 contextual,就可以為它寫一個 identity mapping。
相關:higher-order-unification/explanation.md at master · jozefg/higher-order-unification --- github.com
racket 中的有界續延如何實作 effect system 的功能? [cs-000G]
racket 中的有界續延如何實作 effect system 的功能? [cs-000G]
討論如何用 racket 中的 continuation 實作 effect system 的概念
一個 effect system 大概做了什麼,我們從 effekt 語言 (https://effekt-lang.org/) 這個案例著手
- 一個簽名
effect yield(v : Int) : Bool - 一個 handler
try { ... } with yield { n => ...; resume(n < 10) } - 在
try區塊中調用的函數f可以用do yield(k)來調用 handler - 當
f執行到do yield(k),就會跳轉到with yield中繼續進行,並且n = k - 當程式執行到
resume就會跳回去f之後的do yield(k)的續延繼續執行
因此 exception 系統也可以被視為,沒有調用 resume 的 effect handler,讀者或許也想出數種使用方法了吧?這正是 effect system 的價值。而 racket 擁有比 effect handler 更複雜的機制(continuation with marks),不過 effect handler 機制具有保障使用者不容易出錯的好處,因此在 racket 中模擬一套 effect system 依然有意義,也是有趣的挑戰。
call/prompt [rkt-0000]
call/prompt [rkt-0000]
call/prompt 的主要功能,就如其名稱,是為被呼叫的函數提示一個標記,這個標記在 abort/cc 會被使用。完整的 call/prompt 調用是
(call/prompt f tag handler args ...)
f 是被調用的函數,中間的 tag 是標記,handler 是處理標記的函數,剩下的都是 f 的參數。讀者可以想像成
(with-handler [tag handler] (f args ...))
abort/cc [rkt-0001]
abort/cc [rkt-0001]
abort/cc 的調用是
(abort/cc tag vs ...)
tag 當然就是先前 prompt 寫進去的 tag,而 vs ... 則作為呼叫 handler 的引數
(handler vs ...)
Continuation prompt tag 的產生方式 [rkt-0002]
Continuation prompt tag 的產生方式 [rkt-0002]
調用 (make-continuation-prompt-tag) 產出,這個函數還可以接受一個 symbol 產生可讀的識別碼,並且每次調用這個函數,產生的 tag 都算是不同的 tag,勿必要儲存好這個實體。
要想實現 exception 目前的程式已經完全充分了,只要寫下
(define (f params ...)
(abort/cc tag "cannot read file ..."))
(call/prompt f
tag
(λ (err)
(printf "got err ~a~n" err))
args ...)
即可。事實上 racket 自身的的 exception 也是這樣實作的,要考慮的問題是,前面我們看過 resume 可以跳回去被呼叫的函數!這是如何做到的?
call/cc [rkt-0003]
call/cc [rkt-0003]
call/cc 這個函數是 call with current continuation 的意思,比如說在下面的程式碼中
(* 2 1)
1 的 continuation 就是把 1 挖掉留下的 (* 2 hole),故下列程式碼
(* 2 (call/cc (λ (k) (k 1))))
的結果是 2。讀者可以想像 k = λ (hole) (* 2 hole),這在實作上不太正確,但對理解很有幫助。
一般來說,racket 的函數會簡單的寫成
(define (f params ...) stmt1 ... stmtn)
如果我在其中安放一個 call/cc 會發生什麼事呢?
(define (f params ...) ... (call/cc (λ (k) ...)) stmtk ...)
答案是 k = λ () (begin stmtk ... stmtn)。由於 racket 自動把
stmt1 ... stmtn
包裝成 (begin stmt1 ... stmtn),而
(begin stmt1 stmt2 ...)
中 stmt1 的 continuation 是 (begin stmt2 ...),以此類推就很容易理解 k 等於什麼了。
我們正是需要使用 call/cc 來做出 resume 的效果。
實現 resume [cs-000H]
實現 resume [cs-000H]
在 f 中我們寫下
(define (f params ...) (call/cc (λ (k) (abort/cc tag k ...))))
在 call/prompt 的 handler 中新增一個 resume 參數,這樣就完成了。讀者可以填補下面的程式中的空白來檢驗結果,也充當練習
(define (f params ...)
(call/cc (λ (k) (abort/cc tag k ...)))
...)
(call/prompt f
tag
(λ (resume ...)
...
; 跳回 f 繼續
(resume))
args ...)到這裡我們已經有了運行的基礎,要改善有幾個方向可以參考
- 用 macro 包裝語法
- 放到 typed/racket 中加上 effect 類型檢查確保使用者沒有漏掉 handler:typed/racket eff
- 支持 finally handler,保證任何退出行為都會被這個 handler 攔截(考慮 racket 的函數
dynamic-wind)
使用 TLA+ 的第一步 [tla-0000]
使用 TLA+ 的第一步 [tla-0000]
由於很多 TLA+ 入門教學似乎都沒有談到實務上要從哪裡開始使用 TLA+,所以這裡我想介紹實際上要怎麼做。一個 TLA+ 的檔案以 .tla 為副檔名,其中由 --- MODULE name --- 開頭,由 === 結尾,例如
---- MODULE plustwo ---- =====
在其中可以引用模組,寫成 EXTENDS xxx, yyy, ...
---- MODULE plustwo ---- EXTENDS Integers =====
使用 PlusCal 語言 [tla-0001]
使用 PlusCal 語言 [tla-0001]
比起直接寫出 Spec 等不變式,先寫 PlusCal language (https://lamport.azurewebsites.net/tla/tutorial/intro.html) 的程式再使用用它生成的 Spec 不變量會更簡單也更實用。因為 TLA+ 會嘗試生成所有可能的狀態,有可能出現所謂的 unbound model (https://learntla.com/topics/unbound-models.html),就結果而言對它進行檢查永遠不會完成。用 PlusCal 語言寫的程式相對容易發現這種錯誤。
---- MODULE plustwo ----
EXTENDS Integers
CONSTANT Limit
(* --algorithm plustwo
variables x = 0;
begin
while x < Limit do
x := x + 2;
end while;
end algorithm; *)
\* BEGIN TRANSLATION (chksum(pcal) = "3f62e9ff" /\ chksum(tla) = "239a9ecd")
\* END TRANSLATION
=====
由 PlusCal 產出的不變量會被包在 BEGIN TRANSLATION 到 END TRANSLATION 裡面,可以發現它還會檢查 checksum。由於這個區塊內的程式會被機器生成的內容覆蓋,因此千萬不要把自己寫的不變量放在這個區塊中。
上面的 CONSTANT Limit 可以在 model 的設定檔 .cfg 中指定,這是為了避免把常數寫死在 TLA+ 主程式中,好在檢查前可以進行修改。
增加不變量 [tla-0002]
增加不變量 [tla-0002]
在有了這些程式之後,可以開始增加自己的不變量
Even(x) == x % 2 = 0 IsInc == x >= 0 Inv == IsInc /\ Even(x) THEOREM Terminated == Spec => Termination
IsInc要求x總是大於初始值0Even(x)要求我們寫的程式只會產生偶數Inv把所有我們想證明的不變量組合在一起,/\表示邏輯的「a 且 b」語句。我想很容易猜到\/表示邏輯的「a 或 b」語句
THEOREM 部分宣告 Spec 蘊含 Termination 不變量,這兩者都是 PlusCal 產生的,所以不用太在意細節,這裡的意義是證明程式確實會終止。
這裡介紹了 TLA+ 如何運作,TLA+ 對現實程式的幫助會體現在編寫非同步的程式時,TLA+ 擅長對只有有限狀態、可以使用經典邏輯推導的程式進行檢查,主要可以發現死鎖與違反不變式等錯誤。對 TLA+ 所使用的數學方面的學習可以參考 Lamport 本人寫的 A Science of Concurrent Programs。
The concept of webmention [webmention-0000]
The concept of webmention [webmention-0000]
Each web page should provide the following content (use my site dannypsnl.me as example) in
<link href="https://dannypsnl.me/webmention-endpoint" rel="webmention" />
sender view [webmention-0001]
sender view [webmention-0001]
According to webmention spec, if someone tries to notify my site that there is a link mentions my post, she has to do the following:
curl -I https://dannypsnl.me/xxxto get my webmention endpoint in thehead- post the data, where
is the link refers to my postPOST /webmention-endpoint HTTP/1.1 Host: dannypsnl.me Content-Type: application/x-www-form-urlencoded source= target=https://dannypsnl.me/xxx
receiver view [webmention-0002]
receiver view [webmention-0002]
Therefore, a receiver is a POST handler. According to spec, we can
- return http code
201withLocationin header pointing to the status URL - return http code
202and asynchronously perform the verification - return http code
200and synchronously perform the verification (not recommended), by section 3.2.2Webmention verification should be handled asynchronously to prevent DoS (Denial of Service) attacks.
Verification
- The receiver must check that
sourceandtargetare valid URLs [URL] and are of schemes that are supported by the receiver. (Most commonly this means checking that thesourceandtargetschemes are http or https). - The receiver must reject the request if the
sourceURL is the same as thetargetURL. - The receiver should check that
targetis a valid resource for which it can accept Webmentions. This check should happen synchronously to reject invalid Webmentions before more in-depth verification begins. What a "valid resource" means is up to the receiver. For example, some receivers may accept Webmentions for multiple domains, others may accept Webmentions for only the same domain the endpoint is on.
If the receiver is going to use the Webmention in some way, (displaying it as a comment on a post, incrementing a like counter, notifying the author of a post), then it must perform an HTTP GET request on source, following any HTTP redirects (and should limit the number of redirects it follows) to confirm that it actually mentions the target. The receiver should include an HTTP Accept header indicating its preference of content types that are acceptable.
Error response
If the Webmention was not successful because of something the sender did, it must return a 400 Bad Request status code and may include a description of the error in the response body.
However, hosting a receiver can be annoying, so we should build on the top of some existed tools.
無外部空間下如何考慮幾何空間的測量? [math-0001]
無外部空間下如何考慮幾何空間的測量? [math-0001]
metric 就是在測量長度。不過在歐式空間裡面討論嵌入其中的曲面時,曲面有外部空間切向量,也就是歐式空間的向量可以使用。如果曲面沒有外空間,就需要自己做一個出來,這就引出了 Riemann metric 的想法:對可微分流形 的每一點 考慮抽象的切空間 (不考慮 到底是什麼),重點是隨點附上內積函數 ,因為是模仿內積所以有 bilinearity, positive-definiteness, symmetry 等性質
現在考慮曲線 ,在每一點度量 向量並積分(加起來)即是曲線長度。又隨著區間 改變,會有對應變化的 點,因此模仿並定義
是 norm 的定義,積分因為是跟著 變化,因此依賴 的參數 來定義。如此一來就可以問下一個問題:根據 是從 到 的最短曲線是誰,這就是曲面上的直線的概念(然而,全域與局部最短線,是不一樣的問題,考慮整體將會複雜許多)。
https://qi.bookwar.info/pi-day-special-manifold 對 Manifold 這個想法的高層次概念進行介紹。
Soundness and completeness [math-0000]
Soundness and completeness [math-0000]
- Classical logic's soundness says, if , then is classically valid.
- Classical logic's completeness says, if is classically valid, then .
可以看到,要用 soundness 與 completeness 時,是在關心特定屬性 p,我們說一個系統 sound 就是在問「系統能導出的結果是否滿足 p」;我們說一個系統 complete 則是在問「滿足 p 的結果是否皆能從系統導出」。
understanding -algebra [math-000E]
understanding -algebra [math-000E]
To understand -algebra, we will need some observations, the first one is we can summarize an algebra with a signature. For example, monoid has a signature:
or we can say ring is:
The next observation is we can consider these as objects in a proper category , at here is a [cartesian closed category](math-000D). For example
- monoid is a -morphism
- ring is a -morphism
Now, we generalize algebra's definition.
Definition. -algebra (algebra for an endofunctor) [math-000F]
Definition. -algebra (algebra for an endofunctor) [math-000F]
With a proper category which can encode the signature of , and an [endofunctor](math-001T) , the -algebra is a triple:
where is a -morphism.

With the definition of -algebra, -algebras of a fixed form a category
Definition. category of -algebras [math-000G]
Definition. category of -algebras [math-000G]
For a fixed endofunctor in a proper category (below notations omit fixed ),
- the F-algebras form the objects of the category,
- morphisms are homomorphisms of objects , composition is given by functor laws.
A homomorphism is a -morphism makes below diagram commutes.

We can extra check identity indeed works.

There is a theorem about the initial object of the category.
Theorem. Lambek's [math-000H]
Theorem. Lambek's [math-000H]
The evaluator of an initial algebra is an isomorphism.
Proof
Let be an initial in the -algebra category, the following diagram commutes for any -object

Now, replace with , we have commute diagram

Then we consider a trivial commute diagram by duplicating the path

Combine two diagrams, then we get another commute diagram

By definition now we know is a homomorphism, and since is an initial, we must have
Therefore, we also have
so is the inverse of , proves is an isomorphism.
catamorphism [math-000I]
catamorphism [math-000I]
The theorem actually proves the corresponding -object of initial algebra is a fixed point of . By reversing with its inverse, we get a commute diagram below.

In Haskell, we are able to define initial algebra
newtype Fix f = Fix (f (Fix f)) unFix :: Fix f -> f (Fix f) unFix (Fix x) = x
View as constructor Fix, as unFix, then we can define m = alg . fmap m . unFix. Since m :: Fix f -> a, we have definition of catamorphism.
cata :: Functor f => (f a -> a) -> Fix f -> a cata alg = alg . fmap (cata alg) . unFix
An usual example is foldr, a convenient specialization of catamorphism.
anamorphism [math-000J]
anamorphism [math-000J]
As a dual concept, we can draw coalgebra diagram

and define anamorphism as well.
ana :: Functor f => (a -> f a) -> a -> Fix f ana coalg = Fix . fmap (ana coalg) . coalg
I mostly learn F-algebras from Category Theory for Programmers, and take a while to express the core idea in details with my voice with a lot practicing. The article answered some questions, but we always with more. What's an algebra of monad? What's an algebra of a programming language (usually has a recursive syntax tree)? Hope you also understand it well through the article and practicing.
Theorem. A space is Hausdorff iff its diagonal map is closed [math-000B]
Theorem. A space is Hausdorff iff its diagonal map is closed [math-000B]
The proposition says a space is Hausdorff if and only if its diagonal map to product space is closed, which given an alternative definition. Notice that close means its complement is open. The definition of is
Not hard to see below argument also applies to all finite -product spaces.
Proof
(Hausdorff => diagonal map is closed) Hausdorff means every two different points has a pair of disjoint neighborhoods , where and . Therefore, every pair not line on the diagonal has cover them. The union of all these open sets covers , so the complement of the union is closed.
(diagonal map is closed => Hausdorff) Since
is open, which implies for all the pair . Since , this implies the fact that .
Also, for all and , it's natural that , since the open set at most cover .
Consider that reversely again, that means for all , pair (i.e. will not cover any part of diagonal), that implies as desired.
Lawvere's fixed point theorem 的陳述與應用 [math-0005]
Lawvere's fixed point theorem 的陳述與應用 [math-0005]
這篇文章試著介紹 Lawvere's fixed point theorem 的意義與應用
Theorem. Lawvere's fixed point [math-0006]
Theorem. Lawvere's fixed point [math-0006]
DIAGONAL ARGUMENTS AND CARTESIAN CLOSED CATEGORIES
在一個 cartesian closed category 中,如果 是 point-surjective,則所有 都存在不動點 (滿足 )。
Proof
首先畫出交換圖

其中 的定義是 ,所以對 來說 。沿著這個定義,我們知道 。根據 point-surjective 我們知道 對每個 來說都是唯一確定的。現在把往下方 的 也畫出,即可得出等式:
換句話說 的不動點即是
Example. 應用到 lambda calculus [math-0007]
Example. 應用到 lambda calculus [math-0007]
編碼的方式是找一個只有兩個物件 的 category ,讓 lambda calculus 的 terms 是 -morphisms,這些技巧在 Categorical semantic 領域內相當常見。
到這裡必須檢查 lambda calculus 確實存在 point-surjective,歡迎自行嘗試。
按此編碼後可以得到 。套到等式上
可以得到以下編碼
把 改寫成 ,於是等式可以寫成 ,而函數套用語法可以用 退化,於是得到
注意到 的定義是非遞迴的,因此一定是可定義的。
計算即可發現確實 。因為所有的 -term 都屬於 ,所以現在我們知道任何 lambda calculus 的函數都有不動點。
Example. 應用到 Cantor's theorem [math-0008]
Example. 應用到 Cantor's theorem [math-0008]
取 category 並令 就可以證明 [Cantor's theorem](math-0059)。我們需要引理
Lemma. no point-surjective morphism [math-0009]
Lemma. no point-surjective morphism [math-0009]
If there exists such that for all , then there has no point-surjective morphism can exist for .
This is a reversed version of Lawvere's fixed point, no need an extra proof.
Proof
存在 令所有 都滿足 ,所以對任何集合 都不存在 的 point-surjective 函數,因此也不存在 。
這個定理也可以用到 Gödel incompleteness、Tarski definability 等等問題上。論文 Substructural fixed-point theorems and the diagonal argument: theme and variations 更進一步的簡化了前置條件。
子類型與多型(泛型) [tt-000L]
子類型與多型(泛型) [tt-000L]
這個文章源自下面的問題
不過想問問專業的⋯⋯Golang 都有 interface 這種東西,提供泛型的必要性是什麼啊?
這是個常見的誤解,因為大部分語言不會多認真跟你講清楚到底啥是啥,看來好像都能接受多種不同的類型輸入不是嗎?所以這裡我們就來看各種機制的定義跟差別。
Go 的 interface [tt-000M]
Go 的 interface [tt-000M]
Go 語言的 interface,範例如下
type Abser interface {
Abs() float64
}
其中的 Abs() float64 可以被改寫成抽象語法 Abs : () -> float64。因此一個 interface 有一組與其關聯的一系列簽名 。並且,對 Go 而言下列的兩個 interface 並沒有差異
type A interface {
F(C) D
}
type B interface {
F(C) D
}
因此我們可以更進一步認為 Go 的一個 interface 可以完全由其簽名 替換。
Java 的 interface 與 bounded polymorphism (bounded quantification) [tt-000N]
Java 的 interface 與 bounded polymorphism (bounded quantification) [tt-000N]
在 Java 之中可以定義 interface,範例如下
interface Comparable{ int compareTo(T other); }
相較於 [Go 中不用明確宣告](tt-000D),在 Java 中實現 interface I 需要寫成 class T extends I,因此雖然 Java 的 interface 也有其相關的一組簽名 ,但兩個有同樣簽名 的 interface 不是同一個型別。
而在 Java 中 bounded polymorphism 指的是以下的 interface 使用方法:
<S extends Comparable> S min(S a, S b)
這會使得沒有明確宣告實現 Comparable 的型別無法被傳為 min 的引數。
問題所在 [tt-000O]
問題所在 [tt-000O]
現在考慮一個簽名
在 Java 裡面可以確實保證兩個參數跟回傳的型別都是同一個。在 Go 裡面這個簽名就只能寫成
而兩個參數跟回傳的型別不一定相同。現在我們就會發現乍看之下 interface 對類型的約束跟多型一樣可以被多個不同的型別滿足,但事實上根本就是不同的東西。
interface 是一種子類型關係,換句話說當 實現 我們就說 ,在每個要求 的位置都可以用 取代。
多型的本體是一個型別等級的參數!在語意學上,上面的簽名可以改寫成 ,當你寫下
的時候,乍看之下是一個完整的呼叫。實際上編譯器會先推導 的類型,記作 ,譬如假設 則 ,這時候就可以做型別替換 得出 。因此真正的呼叫程式碼是
子類型規則並不能取代替換這個語意。在 Java 的 規則下,僅是多檢查了 是否為真,子類型與多型仍然是不同的規則。
Gödel incompleteness theorem 到底證明了什麼? [math-0002]
Gödel incompleteness theorem 到底證明了什麼? [math-0002]
哥德爾不完備定理是一個相當有趣的邏輯學發現,要了解他的意涵,要先考慮哥德爾的編碼
哥德爾數(Gödel number)是一種編碼方式,在一個算術系統裡面,當我們把每個字符都排成一個有限的列,我們可以幫每個字符都指定一個自然數。具體來說,我們可能會寫下
- 是 ,其後設意義為「否定」
- 是 ,其後設意義為「或」
- 是 ,其後設意義為「且」
當有符號 ,其對應的哥德爾數為 。我們並不是真的關心具體的每個符號,我們做這件事的理由是為了表示哥德爾編碼。所以這裡要開始定義哥德爾編碼,首先先看一個簡單的例子:當有系統的公式符號排列 ,我們說公式的哥德爾編碼為 。
因此用函數 指示一個公式的每個位置 符號的 Gödel number,則哥德爾編碼確切的定義是
,也就是將質數以每個符號對應的哥德爾數為指數,將它們全部乘起來。這個辦法只是為了迫使每個公式有對應的編碼存在。我們用 記號表示公式 的哥德爾數。
函數給出第 個出現符號的在表中的位置。
在承認前述的系統 下,可以開始描述。
Definition. substitution [math-0004]
Definition. substitution [math-0004]
表示將公式 中哥德爾數為 之符號換成 的哥德爾數再求此替換後公式的哥德爾編碼。
例如
Theorem. Gödel incompleteness [math-0003]
Theorem. Gödel incompleteness [math-0003]
- 存在形式上不能證明卻是真確、可寫下的公式
- 用系統證明自身的一致性會導致不可決定的公式也被證明
Proof
首先,用 表示有哥德爾數為 的公式在系統 中得到證明,而 是其演示
哥德爾有一段很長的論證(證明這是原始遞歸函數),來說明這是可以被 表示的,這裡跳過了這部分論證。且這也是為什麼要求系統 是具備算術能的,因為表示編碼需要自然數算術。
定義 ,但 是未知量,隨意給一個還沒被使用來編碼的數字即可,比如 。於是我們重寫成 。
現在構造 ,求其哥德爾編碼 可以發現正是 所表示的編碼,因為
因此用 替換 中的 ,會得到
可以發現 的後設含義正是「有哥德爾編碼為 的公式沒有系統 中的證明」,然而
- 假設 可以在 中證明為真,就告訴我們 對應的公式不存在任何演示可以於 中證明,但那就是我們剛證明的公式 。
- 假設 可以在 中證明為否,就導出 對應的公式在 中有演示,但那就是我們剛證否的公式 。
綜合可知這意思就是 可證,若且唯若 可證否,是故承認 就是承認 不一致;反之,若 一致則 形式上就不可決定。
巧妙的是,並不難看出 的 meta 陳述是真確的,因為確實不存在任何整數作為編碼滿足這個性質。換句話說,存在形式上不能證明卻是真確、可寫下的公式,這就是第一不完備定理。接著根據第一不完備定理知道了 的真確性,卻在 中形式上不可決定,所以 不能證明一個真確的算術公式,因此 必定是不完備的,這就是第二不完備定理。
因此在 The Blind Spot: Lectures on Logic 中可以看到其陳述更加關注核心:對一個足夠編碼自己又一致的系統
- 存在一個真確的公式 不可決定
- 系統證明自己具有一致性會連帶證明這個不可決定的公式,所以系統無法證明自己的一致性
換句話說,要關心的並不是具體如何構造上面陳述的編碼,而是這類系統編碼系統自身的普遍性問題。
型別有多大? [tt-000E]
型別有多大? [tt-000E]
不久之前看到fizzyelt 的文章,所以我前幾日開始研究自己以前寫的 strictly positive 筆記,因此找到了 Andrej Bauer 在 stackexchange 的回答,整理後寫了這篇文章解釋何謂型別的大小
型別的大小 [tt-000F]
型別的大小 [tt-000F]
要了解型別的大小的意義,可以先考慮一個 small cartesian closed category ,令型別是範疇 的物件(視為只有一個型別的 context)。
應用 slice category [tt-000H]
應用 slice category [tt-000H]
在這個情況下,對任意型別 ,slice category 表示「到達 的 morphism」所構成的範疇,也就是 的 objects 與 triangle morphisms。
Example. 從 出發 [tt-000I]
Example. 從 出發 [tt-000I]
接著,我們要關心其中沒定義的 morphism,我們將基於此集合討論型別 有多大。技術上來說,是指從 terminal object 出發的所有 morphisms(記為 ),這些 morphisms 對應到內建的形式;以邏輯來說是指公理,而在函數式語言裡面,我們最常看到的定義公理的方式就是 data type!換句話說,型別的大小由建構子決定:
- 是 False / Empty type,沒有任何建構子
- 是 Unit type,只有一個建構子
- 是 Bool type,只有兩個建構子
依此類推可以知道有 個單元建構子(即建構子 c 滿足 c : K )的型別 K 可以解釋為 -type,接著 的元素應該有幾個呢?答案是 ,同理我們可以建立 的關係式。
依此可以建立一個簡單的直覺是 c : T 表示 ,而更加複雜的型別如 c : (2 -> T) -> T 就表示 ,建構子的參數表現了型別增長的速度,決定了型別的大小。
一個常見的案例是自然數,我們通常定義 和 兩個建構子來表示自然數 。用 F-algebra 來表示,可以得到 ,從沒有循環參考的角度來看,當前 的大小即取決於上一個 的大小。畫出交換圖就可以了解到從基本點 出發,只有 一個方向可以前進,恰恰就是可數無限大的定義,是以看到這與歸納法的對應時,應當不會太過驚訝。
inductive data type [tt-000J]
inductive data type [tt-000J]
在 dependent type 語言裡面,data type 會變成 inductive data type,引入了更多的限制,而其中跟大小有關的限制就是這裡想要討論的。
Question. 在定義建構子時 c : (T -> T) -> T 有參數 ,試問 有多大?
答案是不知道,因為我們根本還不知道 到底是什麼。
當 定義完畢之後,這個簽名用在函數上倒是沒有問題,因為其大小已經確定,不會遇到自我指涉引發的麻煩。
雖然可以用公理強迫 有 size,但這樣做一來會破壞計算性;二來會顯著的複雜化 termination check。舉例來說,要是容許定義 c,就可以寫出
def foo (t : T) : T := match t with | c f => f t
接著 foo (c foo) 就會陷入無限迴圈,為了要有強正規化,我們希望排除所有這類型的程式,比起一個一個去比對,直接禁止定義 c 這類的建構子可以更簡單的達成目的。Haskell/OCaml 的 data type 則不做此限制,因為它們不需要強正規化,這也是為什麼 dependent type 語言常説其 data type 是 inductive data type,並不輕易省略 inductive 這個詞,因為這樣定義的類型滿足 induction principle。
另外一提,Bauer 談到所有建構子都是為了符合 的形式,有興趣的讀者可以著手證明。此外實現檢查機制時,strictly positive 的遞迴定義可能更適合作為參考。
遞迴 [tt-000G]
遞迴 [tt-000G]
把程式作為 object,而 continuation 作為 morphism,就可以發現尾遞迴完全對應到迴圈這個抽象,兩者都有
- base case 與 break
- induction case 與 next step
這兩個 morphism。從構造的角度來看,還可以說他們跟自然數有對應,上面的簽名恰恰正是 initial 跟 step。
分形遞迴(Tree Recursion) [tt-000K]
分形遞迴(Tree Recursion) [tt-000K]
典型的情況是 fibonacci 數列,展示了前面的型別大小如何與程式相關,常見的程式定義如下
def fib : Nat → Nat | 0 => 1 | 1 => 1 | n+2 => fib n + fib (n+1)
為了抽出計算部分的代數,我們用 inductive type 定義其計算
inductive Fib (a : Type) : Nat → Type where | z : a → Fib a 0 | o : a → Fib a 1 | s : Fib a n → Fib a (n+1) → Fib a (n + 2)
可以看到 induction case 就是 ,所以對應的程式就是兩次呼叫 fib n + fib (n+1) 。當然,因為 fibonacci 還有一個利用矩陣計算的編碼
這個方法對應到 的演算法,因此 fibonacci 不一定要用分形遞迴計算。這件事也告訴了我們代數簽名有時候比我們具體的計算更寬鬆,上面的 inductive type 並未限制如何使用 s,也因此可以摺疊時可能存在更快的計算方式。這也說明了當遇到 c : (T -> T) -> T 一類的建構子時,其對應的計算難以寫出的問題,也就是前面沒辦法定義 的大小的情形。
Parser combinator:文法規則就是組合子的運用 [cs-0009]
Parser combinator:文法規則就是組合子的運用 [cs-0009]
Definition. 左遞迴 [cs-000A]
Definition. 左遞迴 [cs-000A]
左遞迴是我們定義文法的時候會出現的一種形式,比如
翻譯成遞歸下降解析器時會有像下面這樣的程式
def expr : Parsec E := let l <- expr match '+' let r <- expr return E.add l r
這時候 expr 顯然是一個非終止的發散函數,而因為遞迴的原因是運算式的左邊,所以被稱為左遞迴。這樣的 infix 運算形式在文法中很常見,所以我們需要方法來消除文法中的左遞迴。
Definition. Parser combinator [cs-000B]
Definition. Parser combinator [cs-000B]
解析器組合子(parser combinator)最早來自論文 A new top-down parsing algorithm to accommodate ambiguity and left recursion in polynomial time, 在現在的使用中因為不同語言特性跟 parser combinator 指涉的比較像是一種程式方法的情況下,本文中的 parser combinator 是單純指把 parser 跟 higher order function 結合的一種程式方法。這個方案最大的好處就是遞歸下降解析跟程式寫法一一對應,因此相當直覺。
消除左遞迴的方法 [cs-000C]
消除左遞迴的方法 [cs-000C]
現在你知道為什麼我們需要了解遞歸下降解析中消除左遞迴的方式,以下面文法來說
Broken pipe (os error 32)我們可能會將定義改成
Broken pipe (os error 32)這個解法在對應的 parser combinator 中看起來像是
mutual
def term := parse_int <|> parens expr
def expr : Parsec E :=
let l <- term
match '+'
let r <- term
return E.add l r
end擴展到 operator 優先序問題 [cs-000D]
擴展到 operator 優先序問題 [cs-000D]
上面的方法解決了左遞迴問題,但是要是有多個不同優先級的運算形式就會讓文法快速膨脹
Broken pipe (os error 32)這樣單調的修改在文法裡面確實很無聊,不過只要仔細觀察對應的 combinator,就會它們的型別發現這告訴了我們要怎麼利用 higher order function 來解決重複的問題!對 infix 運算形式(左結合)來說,通用的程式是
def infixL (op : Parsec (α → α → α)) (tm : Parsec α) : Parsec α := do let l ← tm match ← tryP op with | .some f => return f l (← tm) | .none => return l
這個 combinator 先解析左邊的 lower tm ,接著要是能夠解析 op 就回傳 op combinator 中存放的函數,否則就回傳左半邊的 tm 結果。使用上就像這樣
mutual
def factor : Parsec Expr
def expr : Parsec Expr :=
factor
|> infixL (parseString "*" *> return Expr.mul)
|> infixL (parseString "+" *> return Expr.add)
end
- 其中
parseString是個假設會進行 whitespace 過濾並 match 目標字串的 combinator Expr.mul跟Expr.add的型別被假設為Expr → Expr → Expr
這裡真正發生的就是使用組合子編碼了文法的層級,其中每個規則都被記錄成匿名函數,我們無需再另外命名。
處理優先度相同的運算子 [cs-000E]
處理優先度相同的運算子 [cs-000E]
因為有些運算子優先級相同,所以我們還需要再修改上面的函數來正確的支援這個概念;而且上面的程式為了避免複雜化,只解析一次 operator 加上 tm 就退出了,會導致實際上 1 + 2 * 3 * 4 這種算式的 * 4 部分沒有被解析。要解決這個問題,我們需要貪婪解析右半邊 op tm 的部分。綜上所述我們得到的程式碼是
def infixL (opList : List (Parsec (α → α → α))) (tm : Parsec α)
: Parsec α := do
let l ← tm
let rs ← many do
for findOp in opList do
match ← tryP findOp with
| .some f => return (f, ← tm)
| .none => continue
fail "cannot match any operator"
return rs.foldl (fun lhs (bin, rhs) => (bin lhs rhs)) l
首先我們有一串 operator 而非一個,其次在右邊能被解析成 op tm 時都進行解析,最後用 foldl 把結果轉換成壓縮後的 α
我希望這次有成功解釋怎麼從規則對應到 parser combinator,所以相似的規則可以抽出相似的 higher order function 來泛化,讓繁瑣的規則命名變成簡單的函數組合。這個技巧當然不會只有在這裡被使用,只要遇到相似形的文法都可以進行類似的抽換,相似的型別簽名可以導出通用化的關鍵。
Appendix. 其他 expression combinator [cs-000F]
Appendix. 其他 expression combinator [cs-000F]
在這裏提到的所有程式都實作在我幫 lean 寫的一個解析器擴充程式庫 https://git.sr.ht/~dannypsnl/parsec-extra 中
右結合的 infix
partial def infixR (opList : List (Parsec (α → α → α))) (tm : Parsec α)
: Parsec α := go #[]
where
go (ls : Array (α × (α → α → α))) : Parsec α := do
let lhs ← tm
for findOp in opList do
match ← tryP findOp with
| .some f => return ← go (ls.push (lhs, f))
| .none => continue
let rhs := lhs
return ls.foldr (fun (lhs, bin) rhs => bin lhs rhs) rhs
prefix op tm
def «prefix» (opList : List $ Parsec (α → α)) (tm : Parsec α)
: Parsec α := do
let mut op := .none
for findOp in opList do
op ← tryP findOp
if op.isSome then break
match op with
| .none => tm
| .some f => return f (← tm)
postfix op tm
def «postfix» (opList : List $ Parsec (α → α)) (tm : Parsec α)
: Parsec α := do
let e ← tm
let mut op := .none
for findOp in opList do
op ← tryP findOp
if op.isSome then break
match op with
| .none => return e
| .some f => return f e什麼是啟動編譯器? (bootstrap compiler) [cs-0001]
什麼是啟動編譯器? (bootstrap compiler) [cs-0001]
當一個語言逐漸成熟,開發者常常會有一個想法就是用自己開發的語言寫這個語言的編譯器,但是這個決策會導致程式庫中有兩套目標一樣但是實現語言不同的編譯器程式。其一是本來的實現,另一個是用語言自身新寫的。一來這樣開發任何新功能的時候都需要寫兩次;二來這會減少可能的參與者人數,因為這下他得要熟悉兩個語言才行!解決這個問題的辦法就是啟動編譯器,通常是一個在多平台上可以直接執行的檔案。
運作原理 [cs-0002]
運作原理 [cs-0002]
約略是下面描述的樣子:
- 語言本身後端的目標語言可以生成這個啟動編譯器,讓我們先用可執行檔簡單理解它,後面再闡述為什麼用普通的可執行檔可能不是一個好主意
- 每次編譯器用到新的特性的時候,都需要更新啟動編譯器檔案並提交進程式庫
- 有了上述準備,就可以在第一次編譯編譯器自身的時候,用啟動編譯器編譯出最佳化過的編譯器執行檔
現在有了最佳化過的編譯器執行檔,就可以正常的使用語言自己對語言自己進行開發了。
現在可以來想一下為什麼是這樣的流程,首先一個程式語言除非被大量作業系統支援(比如 C、Python),否則系統上是不會有這個程式語言的編譯器的!這樣問題就來了:假設有人試圖參與這個編譯器專案,用的平台剛好跟既有開發者都不一樣,請問要由誰提供已經用語言自身編寫的編譯器的編譯器呢?想當然除了一些喪心病狂的作法,是不可能完成這個任務的!所以一個無論如何都已經可以執行的編譯器,哪怕效能比較差,也具有存在的價值。
而語言自身的編譯器用到新功能的時候,也一定要更新啟動編譯器,否則下一輪的新參與者就沒辦法正確的進行初始編譯。
用普通的可執行檔可能不是一個好主意 [cs-0003]
用普通的可執行檔可能不是一個好主意 [cs-0003]
前面提過說啟動編譯器通常是一個在多平台上可以直接執行的檔案,也提過哪怕效能不佳也可以,這兩個理由使得特定平台的可執行檔不是一個好的選擇。 當然,我們也可以選擇維護每個平台的啟動編譯器,chez scheme 就維護了一堆根據不同平台套用組合的二進位檔案做這件事。
回到正題上,啟動編譯器通常不會選擇這麼複雜的方式,而是會生成可以在多平台上執行的檔案。舉例來說,生成 C 或是 Python 這種已經被許多系統廣泛支援的語言,最近 zig 就是使用 wasm 達成這個目標。但這個選擇也不能太過隨便,比如要是語言自己的 type checking 任務很長,生成 Python 就會得到一個大家都不想等它跑完就不玩了的啟動編譯器。而限制太多的語言像是 haskell 或是 rust 可能也不是優秀的選擇,因為你的語言模型很可能跟這些目標語言非常不相配,進而讓編譯過程非常的痛苦。
有了這些概念,我想你已經有能力為自己的語言寫出啟動編譯器了!那麼剩下的篇幅我就可以來寫點 murmur,我覺得這個概念可以進一步推升到選擇一個夠容易編譯出來,也夠容易寫出通用最佳化編譯器的語言來達成。我個人是很看好 wasm,因為它確實容易當目標、最佳化,只可惜現在還有不少重要的功能都沒有定案。llvm 的 bytecode 確實也是一個方案,寫一個把 llvm bytecode 編譯成 executable 的 python 檔案並不困難,但 llvm 的連結性自己就是一個天殺的大麻煩所以這個方案我很少看到有人使用。Java bytecode 則是讓那些本來就預計只在 JRE 生態系內部的語言從一開始就沒有這個問題,微軟的 CLR 也是類似的狀況,缺陷是最後語言受制於 runtime,這個問題會有多大條取決於語言的目的是什麼。
好像是今年最後一天了,祝你不是在今天看到這篇文章的!
polymorphism 的執行期設計 [cs-0000]
polymorphism 的執行期設計 [cs-0000]
在傳統的 ML 或是 Haskell 裡面,有一個型別表現的特別醜陋,就是 data type 表示的 disjoint。 這是因為無論如何,disjoint 就是會需要執行期時有要處理哪個分支的資訊。 因此語言中都設計有 constructor 這麼一個特殊的存在,其中每個 case 都有對應的執行期標籤。 舉例來說,
type bool = false | true
這裡 false 可能就是 0 而 true 是 1。
type nat = z | s of nat
這裡 z 可能就是 0 而 s 是 1 並且接有一個 tuple 放 nat 。
要是這種 disjoint 語義想要完美對應 category theory 的 coproduct,那就需要引入真正的 union type。 要注意到這跟 C 語言的 union 略有不同,C 語言事實上仰賴了開發者完全知道自己在做什麼作為前提, 要求開發者對 union 正確的操作。要是要求 C 語言一樣要能處理不同型別的輸入的話,一樣要放置一個標籤欄位才能解決。 union type 在型別上是很優美,沒有 多餘 的標籤,在 typed/racket 裡面可以記成 (U Integer Boolean String) 之類的。但這個方案遠非毫無缺點,之所以可以這麼做,事實上是因為 racket(以及早期的諸多 functional languages)採用了 universal object 編碼。
Universal object 就是指對每一個執行期的物件,都把型別囊括在內。 這樣一來當然就不需要另外給標籤,因為每個物件本來就都有標籤了。 可想而知,這個方法缺點就是針對需要緊密排列的運用場景效果不佳。 所以 racket 要是需要操作 vector float 這種資料,再怎麼編譯都還是會慢 C 語言一線, 主因就是沒有用最緊密的方式排列資料(多了標籤),相較於 C 沒有利用到當代硬體特性。 但反過來說就沒有 ad-hoc 的編譯難題,因為本來就是需要 runtime 解決的問題就推到 runtime 解決。
那麼可想而知,後來為了適當壓縮物件,ML 跟 Haskell 都走上混合的解決方案。 針對小物件(通常是指小於等於該平台的一個 word 的資料型別)就會盡可能不要包起來,反之就採用 universal object, 在實務上表現也確實不錯。
利用參考等價性質的技巧 [racket-0000]
利用參考等價性質的技巧 [racket-0000]
所謂的使用參考等價性,是指在某些語言裡面,兩個物件是否相同是通過參考而非內容決定的。 舉例來說, racket 裡寫下一個空結構,然後生成一些實例
(struct id ()) (define a (id)) (define b (id)) (define c a)
我們可以用一些 eq? 運算來檢查
> (eq? a b) #f > (eq? a c) #t > (eq? c a) #t > (eq? b c) #f
這樣就可以生成一連串在運行中的程式內唯一的資源標示。
但要小心你用的語言的特性,比如要是我把上面的(struct id ())變成(struct id () #:transparent)並改用equal?運算, racket 就會改用內容而非參考去判定相等。
應用場景
那麼這種技巧可以用在哪些地方呢?首先要注意到這絕對不可以用在序列化上!每次程式重新啟動,同一個宣告都會被重新分配到不同的參考,所以這不能超出程式運行的範疇。 所以合適的用法應該是在程式終止之後就不會再仰賴這個資源唯一性的。
- Racket 自己 Sets of Scopes:在 Matthew Flatt 的 Let's Build a Hygienic Macro Expander 裡,
scope就是一個空結構。 - 型別檢查裡面的自由變數也可以用這個方式生成(這樣我們就不用維護一個 free variables counter)。
- Threading ID: 共時結構要是需要唯一標示的時候,這個技巧就很方便,因為沒有正確運作的記憶體配置器會把物件分配到同一個地方。
這樣的小技巧非常方便,當然也需要注意其限制以及程式語言的實際運作方式。 在使用前最好真的去讀你的語言對參考的處理方式,確保這些程式仰賴的環境假設正確無誤,才不會出現出乎意料的問題。
Algorithm. Strictly positive check [tt-0000]
Algorithm. Strictly positive check [tt-0000]
Why? [tt-0001]
Why? [tt-0001]
strictly positive 是 data type 中對 constructor 的一種特殊要求形成的屬性,這是因為如果一個語言可以定義出不是 strictly positive 的 data type,就可以在 type as logic 中定義出任意邏輯,形成不一致系統。
現在我們知道為什麼我們想知道一個 data type 是不是 strictly positive 了!了解完 strictly positive 的必要性後,我們用例子來理解什麼是不一致的系統,第一個例子是 not-bad :
Example. Not Bad [tt-0004]
Example. Not Bad [tt-0004]
data Bad bad : (Bad → Bottom) → Bad notBad : Bad → Bottom notBad (bad f) = f (bad f) isBad : Bad isBad = bad notBad absurd : Bottom absurd = notBad isBad
Bottom () 本來應該是不可能有任何元素的,即不存在 x 滿足 x : Bottom 這個 judgement,但我們卻成功的建構出 notBad isBad : Bottom。如此一來我們的型別對應到的邏輯系統就有了缺陷。
Example. Loop [tt-0005]
Example. Loop [tt-0005]
現在我們關心一下第二個例子 loop(修改自 Certified Programming with Dependent Types):
data Term abs : (Term → Term) → Term app : Term → Term → Term app (abs f) t = f t w : Term w = abs (λ x → app x x) loop : Term loop = app w w
loop 的計算永遠都不會結束,然而證明器用到的 dependent type theory 卻允許型別依賴 loop 這樣的值,因此就能寫出讓 type checker 無法停止的程式。換句話說,證明器仰賴的性質缺失。事實上 Term 跟 Bad 的問題就是違反了 strictly positive 的性質,或許也有人已經發現了兩者 constructor 型別的相似之處。接下來我們來看為什麼這樣的定義會製造出不一致邏輯。
原理 [tt-0002]
原理 [tt-0002]
首先我們需要理解以下兩條規則
- 蘊含
- 蘊含
根據這兩條規則,我們說 arrow type
- contravariant in (或 varies negatively)
- covariant in (或 varies positively
所以我們稱 為 negative position、 為 positive position
實作 [tt-0003]
實作 [tt-0003]
而 strictly positive 就是說,inductive family 自己不可以出現在 negative position
在 Agda 的文件中也有解釋:任何 constructor 都形如
而每個 都可以不提到 或是形如
不可以等於
文章到這邊告一段落,也解決了我這一年來對證明器實作的最大疑問之一,進一步的解答可以參考 https://cs.stackexchange.com/questions/55646/strict-positivity/55674#55674
Programming 生涯回顧 [2020]
Programming 生涯回顧 [2020]
很久以前就曾經想過要不要寫下這種經驗文,這念頭出現到現在轉眼就過了兩年了 XD。期間真的發生了太多事,現在又到了人生的十字路口所以決定記錄一些東西,希望這篇文章或許能夠啟發一些像我一樣迷惘的人。
大學教育
我接觸程式的時間不是特別早,到了大學才第一次”使用”電腦。那時真的蠻好笑的,我選了這裡的原因是因為我覺得這系名好長好有趣就填在指考志願第一個位置(而我當時也沒有試圖弄懂志願序的用途 XD),亂填的下場就是我爸差點沒氣死。當時幾經考慮,然而最後我還是決定不重考了。因為前進後或許不是一條好的道路,但到時候再後悔就好了,而不前進就必然要耗費一年也未必真的有什麼結果。到了學校,基礎程式課就立刻深深吸引了進了不知道能幹嘛的科系、對未來毫無想法的我。從此我每天從中午 12 點寫程式寫到半夜 3 點,每個禮拜只出現在程式課、書店、圖書館跟房間,搞到很多科都超低空飛過(雖然我也不在意)。印象特別深刻的是當初印出 99 乘法表的作業我硬是搞不懂 loop 的用途,死纏著學長問了 2 小時才寫出來。現在想想,真是佩服學長沒有從此不鳥我呢 XD。大一就在不太懂什麼檔案 IO、資料庫的情況下寫出了人生第一個能夠算是應用程式的程式:課堂的最終測驗,寫出一個運作在 CLI 下的 ATM(當時也不知道什麼是 CLI XD)。大二的資料結構與演算法課程中,小組討論促進了很多有趣的發想跟對演算法的理解(可惜整個科系就只有該門課程的教授這樣上課)。這門課讓我知道很多同學其實都能講出非常有見解的解法,即使他們後來未必會走上開發者這條道路。該課程結束後我跟學長(對,被我纏了 2 小時的那位)更常單獨討論他們當時的專題:為醫療領域優化的搜尋引擎。這個專題重點擺在如何針對特定領域優化搜尋結果,減少搜尋到農場文當然是非常重要的目標之一。由於當時對爬蟲的討論,我開始接觸 Erlang 與 Go 這兩個語言,接著幾個月都在不斷的優化寫好的爬蟲,讓它能夠在最短時間內處理最多的頁面。最後還不小心翻開龍書踏入了 Compiler 的奇妙世界。快樂的時光總是短暫,由於一些經濟因素,我決定休學走上工作的道路。
工作
第一份工作我靠著一個類 python 語言的直譯器說服了老闆為什麼雇用一個高中學歷的人也沒問題 www。現在回想這間公司真的很不錯,只要工作做完就完全不干涉你要做什麼,所以我在這裡寫了不少 Compiler 的程式,還把 redux porting 到 Go 裡面(雖然我到現在也沒弄懂這有什麼意義 XD)。當時朋友都在台北,也因為在家住膩了(結果現在又想回家住了),決定上台北找工作,就在台北待到了現在。剛上台北找工作時有一次很有趣的面試,當時我英文不好(連 Algorithm 都沒聽懂是什麼)、技能樹只往 Compiler 上點,面試官還願意一個一個跟我解釋我的問題在哪裏,最後還鼓勵我有學會的東西都記得很熟練,人真的超好 :),現在還是很感謝他。工作幾年下來,其實慢慢覺得工作帶來的成長不存在了,這也讓我有了想轉換人生跑道的想法,後面會再提。
認識 PLT
在台北工作的兩年多裡慢慢開發著自己的程式語言,隨著得到更多的開發經驗和學習了更多的語言,我逐漸意識到我似乎有什麼根本性的東西根本沒有學到。就像當初我總覺得 Design Pattern 有點怪異、Go 開發者宣稱的簡單似乎不大對一樣的直覺,我發現了 PLT 這個以前從來沒有碰過的領域。從此開始入天坑:lambda calculus -> second order logic -> hindley-milner -> dependent type -> calculus of construction -> MLTT,現在正在讀 cubical type, inductive construction(CIC), HoTT 等。我認為學習 PLT 真的有很大的好處,會逐漸超出單個語言的見解,分解出是什麼讓程式變得好寫而什麼不是。也是對 PLT 的學習讓我終於弄懂為什麼 Go 的設計其實並沒有帶來簡單性、為什麼 Design Pattern 其實沒有必要背誦(甚至沒必要特意學習)。只是隨著了解的深入,我也更不想設計新的程式語言了 www(但又不想廢棄寫很久的專案)。但我不建議對上面的一切沒有興趣還硬讀,cs 有很多事情能做,絕對不只是 PLT。
避免崇拜
我覺得一路走來,最重要的教訓就是不要盲目的崇拜,不只是技術上,在生活中也應該檢視自己是不是做了什麼假設,而不是盲目的用被假設影響後的觀點看待事物。以我個人而言,崇拜過 Go, UNIX 等專案的作者和所謂的 hacker 就是該怎樣,進而導致了很多不良的選擇,例如:硬要用 vim 而不是 IDE、硬要用 CLI 而不是 GUI、明明有現成方案卻要從頭打造整個專案。這不是說用 vim 不對,很多時候我都用 vim。當環境上只有 terminal 或是只是要小改幾行時,我不否認它的編輯能力非常高效,但如果要說起跟 debugger 的整合性、移至定義的精準度、重構的方便度、閱讀其他人的程式碼等等,用 IDE 真的會好很多。關鍵是不要只因為某個看法就放棄對其他可能性的探索。對,就算我推薦 IDE,你還是該學看看 vim 或 emacs,說不準什麼時候就用到了。這也連結到怎麼選擇要學習什麼,只要避免崇拜,就較能以客觀的角度選擇合適的工具。
歸類知識
對知識進行分類是有好處的,記住生命週期長的資訊,而對有生命週期短的資訊不要耗費太多時間。例如說「理解演算法」就比「記住 vim 的 101 個指令」生命週期長的多。這裏,並不只是指事物本身的生命週期,要說起來 vim 活得超久,可能比很多演算法更久,但 vim 是容易過時的,你可能會遇到某些情況 vim 就是沒有 plugin 能用,這時候該做的恐怕不是自己刻個工具而是找替代方案,因為我們通常沒有時間,比起 vim 我更關心我想處理的問題,所以 agda 我用 atom 編輯,因為有方便的套件能用。而演算法就算不是最快的,其發想思路還是有相當的價值。同理對程式語言其實沒有必要花時間掌握語法到能夠「寫出最好的寫法」,因為我們關心的是程式碼解決的什麼問題,不是用什麼程式語言。關鍵是不要為了「非核心」的知識耗費大量心力,若這個「非核心」的知識不是你的興趣也不是你的工作職責。沒錯,如果就是喜歡玩 vim,開發 vim 的 plugin 就是樂趣根源那就去做吧,人類社會之所以能夠運作就是因為每個人是不一樣的。就像 PLT 知識對目標是寫個作業系統的人而言只是「非核心」知識一樣,每個人需要學習的知識都不一樣,所以也沒必要羨慕什麼「大神」,說不準人家還羨慕你能睡好覺,who knows。
下一個階段
雖然我被我講得好像我已經沒有迷惘了似地 XD,但完全不是這樣,我也在考慮去考在職碩士然後出國讀博士走學術這樣的路。人生沒有所謂的成功,有個笑話就說「窮人想有錢,有錢後被權貴欺負,就想著要有權,成官之後整天鬥爭,想想還是平淡的生活好,又成了窮人」,笑話是笑話,但人生沒有最佳解卻是事實,所以就算選了之後後悔也沒關係,需要的只是弄清楚自己接著想做什麼,然後去做。
世界上只有一種真正的英雄主義,那就是在認識生命的真相後,依然熱愛生活。
雖然我說的好像自己什麼都知道了,可惜就算是此時此刻我也搞不清楚我想幹嘛 w,但我還是會繼續學習我有興趣的知識、嘗試看看學術生涯是什麼樣子、體驗不同國家生活的風景。不知不覺就 23 歲,寫了 5 年程式,工作了 3 年,這世上唯一不缺的…大概就是時間不夠的感嘆,希望接下來 3 年也是有趣的人生。
人生不是只有程式碼
最後,人生不是只有程式碼,記得停下來看看那些幫助自己的人,我曾經沒有看清這麼簡單的事實。回憶過往,人生總是在受他人的幫忙,高中時帶給我人生樂趣的數學老師、嘴上抱怨但還是支持我的各種任性決定的父母、大學我整天吃吐司時請我吃飯的同學跟二話不說就借我幾千元的朋友、當初幫我跟老師求情不要當我的同學 www、工作時遇過的同事、在我低潮時聽我講抱怨的廢話的人們,只能再三感謝。這些才是讓我不用擔心,專心開發的支柱,如果有人讀完真的覺得自己沒有這樣的支柱,那也可以寄信給我,雖然我不見得能給什麼建議,保證沒辦法解決問題,但我可以好好聆聽,因為也有曾經願意聽我訴說的陌生人,雖然最後好像跟 programming 根本沒什麼關係 www,但還是希望這篇文章能夠幫助到一些人。話說回來,這部落格真的有讀者?
fun networking: tcp close [programming-0002]
fun networking: tcp close [programming-0002]
Recently we are working on a new feature is about filter packets by HTTP header for our router. This is the concept, we read the header by rules, rules are just some key/value pair. If key missing or value isn't matched, then we drop the packet.
When a connection end, we would remove this connection from allowing pass map.
Anyway, we found a bug is, we use FIN flag to say this packet is the end of the TCP connection, but we know a connection end is a:FIN -> b:ACK -> b:FIN -> a:ACK, a/b is client/server here. So except the first packet, following packets won't pass our router, then connection would never end until timeout, LOL.
Reflection in Go: create a stack[T] [programming-0001]
Reflection in Go: create a stack[T] [programming-0001]
Do you know what can Go's package reflect do?
Whatever you had use it or not. Understanding it is not a bad thing.
A well known thing is Go don't have generic, I'm not going to tell you we have generic, I'm going to tell you some basic trick to have the result like generic.
Take a look on the type Stack
type Stack struct {
stack []interface{}
limitT *reflect.Type
}
limitT is a *reflect.Type, the reason that it's a pointer to reflect.Type rather than reflect.Type is because of we may do not spec it.
We add the Stack by invoke WithT.
func (s *Stack) WithT(v interface{}) *Stack {
t := reflect.TypeOf(v).Elem()
s.limitT = &t
return s
}
Why is reflect.TypeOf(v).Elem()? Because we can't really get an instance that type is an interface! Instead of that, we can get a type is pointer to an interface!
We have a common idiom is using (*SomeInterface)(nil) to get pointer to interface instance.
Now we know that user code can be
type AST interface {
Gen() llvm.Value
}
// main
s := stack.New().WithT((*AST)(nil))
After we do that, user can't push a value do not implement AST. So, how we do that? We do a check at Push
func (s *Stack) Push(element interface{}) {
if s.limitT != nil {
if !reflect.TypeOf(element).Implements(*s.limitT) {
panic(fmt.Sprintf("element must implement type: %s", *s.limitT))
}
}
s.stack = append(s.stack, element)
}
If limitT is not nil, means we do not limit the type, just keep going on. But if we limit the type, we check that element implements limitT or not. If not, we panic the process. Now we have a stack can promise type safe at runtime.
Error is Value [programming-0000]
Error is Value [programming-0000]
I think most Gopher had read error-handling-and-go. Has anyone had watched Go Lift? Let's getting start from Go Lift! The point of Go Lift is: Error is Value. Of course, we know this fact. Do you really understand what that means? In Go Lift, John Cinnamond mentions a trick about wrapping the error by command executor. For example, we create a connection to server:6666 by TCP.
conn := net.Dial("tcp", "server:6666")
Can we? Ah…, No! The correct code is:
conn, err := net.Dial("tcp", "server:6666")
if err != nil {
panic(err)
}
Then we write something through the connection.
nBtye := conn.Write([]byte{`command`})
We want that, but the real code is:
nBtye, err := conn.Write([]byte{`command`})
if err != nil {
panic(err)
}
// using nByte
Next, we read something from server:6666, so we create a reader.
reader := bufio.NewReader(conn)
response := reader.ReadString('\n')
No! We have to handle the error.
response, err := reader.ReadString('\n')
if err != nil {
panic(err)
}
// using response
Howver, the thing hasn't ended yet if we have to rewrite the command if response tells us the command fail? If we are working for a server, we can't just panic? So Go Lift has a solution:
func newSafeConn(network, host string) *safeConn {
conn, err := net.Dial(network, host)
return &safeConn{
err: err,
conn: conn, // It's fine even conn is nil
}
}
type safeConn struct {
err error
conn net.Conn
}
func (conn *safeConn) Write(bs []byte) {
if conn.err != nil {
// if contains error, do nothing
return
}
_, err := conn.Write(bs)
conn.err = err // update error
}
func (conn *safeConn) ReadString(delim byte) string {
if conn.err != nil {
return ""
}
reader := bufio.NewReader(conn.conn)
response, err := reader.ReadString("\n")
conn.err = err
return response
}
Then usage will become
conn := newSafeConn("tcp", "server:6666")
conn.Write([]byte{`command`})
response := conn.ReadString('\n')
if conn.err != nil {
panic(conn.err)
}
// else, do following logic
Can we do much more than this? Yes! We can have an error wrapper for executing the task.
type ErrorWrapper struct {
err error
}
func (wrapper *ErrorWrapper) Then(task func() error) *ErrorWrapper {
if wrapper.err == nil {
wrapper.err = task()
}
return wrapper
}
Then you can put anything you want into it.
w := &ErrorWrapper{err: nil}
var conn net.Conn
w.Then(func() error {
conn, err := net.Dial("tcp", "server:6666")
return err
}).Then(func() error {
_, err := conn.Write([]byte{`command`})
})
Wait! We need to send the connection to next task without an outer scope variable. But how to? Now let's get into reflect magic.
type ErrorWrapper struct {
err error
prevReturns []reflect.Value
}
func NewErrorWrapper(vs ...interface{}) *ErrorWrapper {
args := make([]reflect.Value, 0)
for _, v := range vs {
args = append(args, reflect.ValueOf(v))
}
return &ErrorWrapper{
err: nil,
prevReturns: args,
}
}
func (w *ErrorWrapper) Then(task interface{}) *ErrorWrapper {
rTask := reflect.TypeOf(task)
if rTask.NumOut() < 1 {
panic("at least return error at the end")
}
if w.err == nil {
lenOfReturn := rTask.NumOut()
vTask := reflect.ValueOf(task)
res := vTask.Call(w.prevReturns)
if res[lenOfReturn-1].Interface() != nil {
w.err = res[lenOfReturn-1].Interface().(error)
}
w.prevReturns = res[:lenOfReturn-1]
}
return w
}
func (w *ErrorWrapper) Final(catch func(error)) {
if w.err != nil {
catch(w.err)
}
}
Now, we're coding like:
w := NewErrorWrapper("tcp", "server:6666")
w.Then(func(network, host string) (net.Conn, error) {
conn, err := net.Dial(network, host)
return conn, err
}).Then(func(conn net.Conn) error {
_, err := conn.Write([]byte{`command`})
return err
}).Final(func(e error) {
panic(e)
})